 1 month ago
27
1 month ago
27
AI 기반의 고도화된 분석 파이프라인 구축기

들어가며
요기요에서 리서처로 일한다는 것은
끊임없이 쏟아지는 비즈니스 가설들을 검증하는 과정의 연속입니다.
요기요 UX 리서치 팀은 급변하는 비즈니스 환경에 대응하기 위해
Research Operations(ReOps)에 AI를 적극 통합하여
분석의 밀도와 속도를 동시에 높이는 시도를 이어가고 있습니다.
과거에는 속도에 대한 요구가 리서처에게 압박으로 다가왔으나
지금은 AI를 워크플로우의 핵심 파트너로 배치하여
효율적인 리서치 환경을 구축했습니다.
수많은 녹취록을 다시 들으며 분석하고 보고서를 작성하는
반복되는 고충을 해결하고자 리서치 과정에 AI를 활용했습니다.
그리고 그 결과는 기대 이상이었습니다.
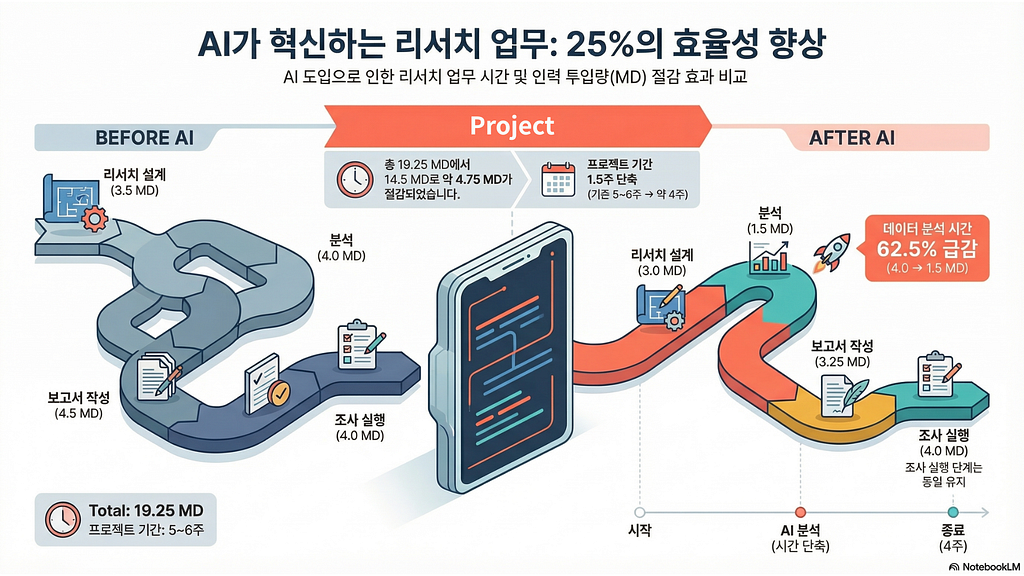
결과적으로 보면, 주 단위로 환산하면 6주 가까이 걸리던 일이
4주 만에 마무리 되어 약 25%의 시간을 아낄 수 있었습니다.
본 게시물에서는 ChatGPT, Gemini Pro, NotebookLM을 활용해
리서치 리드타임을 단축하고 인사이트의 깊이를 더한 과정을 소개합니다.
[Step 1] 리서치 설계: 요구사항의 구조화
조사 요청이 들어오는 단계에서 가장 중요한 것은
‘질문의 본질’을 파악하는 것입니다.
조사 요청이 들어오는 초기 단계에서 가장 큰 리스크는
이해관계자의 모호한 비즈니스 언어입니다.
저는 ChatGPT를 단순한 챗봇이 아닌
비즈니스 요구사항을 리서치 설계로 변환하는 도구로 활용합니다.
왜 ChatGPT인가?
- 논리적 추론 능력: 복잡한 제약 조건과 논리적 맥락을 파악하는 능력이 매우 뛰어납니다. 비즈니스 가설 간의 충돌이나 논리적 비약을 잡아내는 데 최적화되어 있습니다.
- 추상적 개념의 구체화: ‘사용자가 만족하는지 알고 싶어요’라는
추상적인 요구를 ‘재방문 의사, 추천 지수(NPS), 태스크 완료율’ 등
측정할 수 있는 지표로 분해하는 추론 능력이 탁월합니다.
어떻게 활용하는가?
- 가설 해체: 요청서에 담긴 비즈니스 요구사항을 입력하고,
논리적 빈틈이나 모호한 개념을 식별합니다. - 리스크 방지: 설문지나 인터뷰 가이드 제작 시,
응답을 유도하는 질문이 있는지
질문의 흐름이 사용자 경험과 일치하는지 객관적으로 검토받습니다. - 효과: 킥오프 미팅 전 생각이 이미 구조화되어, 이해관계자와의
커뮤니케이션 과정이 획기적으로 줄어듭니다.


[Step 2] 데이터 분석: 비정형 Raw data 체계화
조사 완료 후 쌓이는 방대한 인터뷰 스크립트와
정성적 데이터 분석에는 Gemini Pro를 활용합니다.
왜 Gemini Pro인가?
- 보안과 성능: 기업용 버전을 사용하여 데이터 보안을 유지하면서,
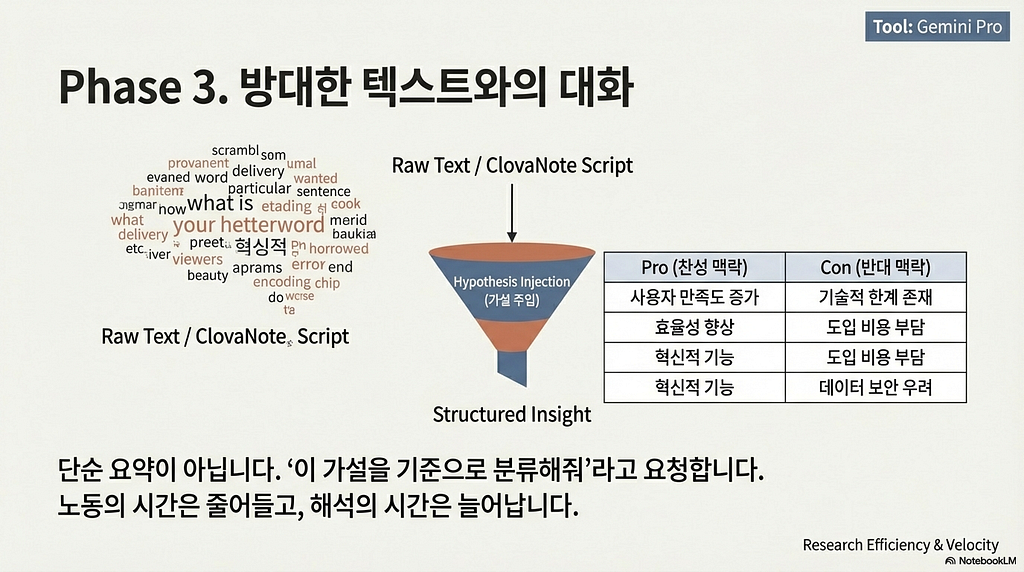
대량의 텍스트에서 패턴을 추출하는 Gemini의 강점을 극대화합니다. - 가설 기반 분석: 단순 요약이 아니라 “이 가설을 기준으로
찬성/반대 맥락을 분류해 줘”와 같은 구체적인 지침을 제공합니다. - 효과: 반복적인 단순 정리 작업은 AI에게 맡기고,
리서처는 데이터 사이의 숨겨진 맥락을 해석하고 전략을 도출하는
본질적인 업무에 집중할 수 있습니다.
End-to-End 리서치 파이프라인 5단계를 소개합니다.
[Phase 1] 대규모 정성 데이터의 구조화인터뷰가 끝나고 나면 수십 페이지의 스크립트가 남습니다.
리서처가 가장 많은 시간을 쓰는 구간이자
주관이 개입되기 쉬운 전사 및 코딩 단계입니다.
저는 이 과정을 자동화하기 위해 5단계의 의미 단위 분석 리서치 방법론을
프롬프트에 녹여냈습니다.
이때 단순히 내용을 묻는 것이 아니라
아래와 같은 구조화된 프롬프트를 설계하여 분석의 일관성을 유지했습니다.
- Role Play: AI에게 UX 리서치 분석 전문가라는 페르소나를 부여해 전문적인 톤앤매너를 유도했습니다.
- Constraint: 한 문장에 하나의 의미만 담도록 제한하여, 이후 클러스터링이 용이하도록 설계했습니다.
- Data Cleaning: 리서처의 질문은 배제하고 사용자의 생각/행동/감정이라는 핵심 데이터만 추출하도록 명령했습니다.
# Task: 인터뷰 스크립트의 의미 단위 분해 및 정제
[Instruction]
아래 제공되는 인터뷰 스크립트를 분석하여 의미 단위로 분해해 줘.
[Constraints]
1. Atomic Unit: 한 문장은 반드시 하나의 의미만 담도록 분리할 것.
2. Filter: 사용자의 생각, 구체적인 행동, 감정이 드러나는 발언 위주로 추출할 것.
3. Clean-up: 모더레이터의 질문이나 단순한 추임새는 제외할 것.
[Output Format]
- [발언]: "사용자의 실제 워딩"
- [의미 요약]: 추출된 문장의 핵심 의도나 페인포인트 요약[Phase 2] 정성 데이터의 정량화: 태깅 및 속성 분류
의미 단위로 분해된 데이터는 파편화되어 있기 때문에,
이를 서비스 개선의 근거로 쓰기 위해서는 분류가 필수적입니다.
저는 AI에게 UX 리서치의 핵심 프레임워크인
Pain Point / Needs / Motivation / Barrier / Value 라는 5가지 태그를
학습시켜 수만 줄의 데이터를 자동 분류했습니다.
- Framework Mapping: UX 리서처가 흔히 사용하는 분석 프레임워크를 태그 기준으로 정의하여 AI와 리서처의 시각을 동기화했습니다.
- Multidimensional Analysis: 단순한 긍/부정 분석을 넘어, 사용자가 ‘왜(Motivation)’ 사용하는지와 ‘무엇이 막고 있는지(Barrier)’를 입체적으로 식별하도록 설계했습니다.
# Task: 사용자 발언 데이터의 속성 태깅 및 해석
[Tag Definition]
- Pain Point: 서비스 이용 중 겪는 구체적인 불편함이나 불만
- Needs: 사용자가 해결하고 싶어 하는 근본적인 요구사항
- Motivation: 서비스를 이용하게 만드는 심리적/환경적 동기
- Barrier: 서비스 이용을 주저하게 만들거나 중도 이탈하게 하는 요인
- Value: 사용자가 서비스를 통해 얻는 효익이나 긍정적 가치
[Output Format]
- [발언]: "사용자 워딩"
- [Tag]: 해당 발언에 맞는 태그 (중복 가능)
- [해석]: 리서처 관점에서의 데이터 함의 기술[Phase 3] 복잡한 데이터의 구조화: 테마 도출
세 번째 프롬프트는 리서치의 꽃이라고 할 수 있는
Affinity Diagram 과정을 자동화하는 핵심 단계입니다.
수많은 포스트잇을 벽에 붙이며 그룹핑하던 아날로그 방식을
비정형 데이터의 클러스터링이라는 기술적 관점으로
재해석하여 프롬프트에 적용해 보았습니다.
- Bottom-up Clustering: 개별 발언에서 시작해 상위 테마로 올라가는 귀납적 분석 방식을 AI에게 학습시켰습니다.
- Representative Selection: 수많은 발언 중 팀원들을 가장 잘 설득할 수 있는 Crucial Voice를 추출하도록 설계했습니다.
- Actionable Insight: 단순한 분류를 넘어, 비즈니스 액션으로 이어질 수 있는 사용자 니즈를 도출하는 데 집중했습니다.
# Task: 태깅된 발언 기반 어피니티 다이어그램(Affinity Diagram) 및 핵심 테마 도출
[Analysis Process]
1. Similarity Grouping: 유사한 태그와 맥락을 가진 사용자 발언들을 논리적으로 그룹핑할 것.
2. Naming: 각 그룹의 핵심 가치를 관통하는 직관적인 '테마 명칭'을 정의할 것.
3. Selection: 해당 테마를 가장 잘 대변하는 대표 발언을 선정할 것.
[Output Format]
- Theme: [테마 이름]
- 설명: 이 테마가 형성된 배경과 사용자의 전반적인 맥락 설명
- 대표 발언: "사용자의 핵심 워딩"
- 사용자 니즈: 이 테마를 통해 해결해야 하는 근본적인 갈증(Unmet Needs)[Phase 4] 데이터 기반의 가설 검증과 의사결정
리서치의 최종 목적은 우리가 세운 가설이 참인지 거짓인지 판별하고,
다음 액션을 결정하는 것입니다. 리서처의 확증 편향을 방지하고
객관적인 가설 검증 파이프라인을 구축했습니다.
- Strict Evidence-Based: 모든 평가는 반드시 앞서 도출된 테마와 Raw data에 기반하도록 강제했습니다.
- Balanced Perspective: 가설을 지지하는 증거뿐만 아니라 기각하는 증거를 동시에 추출하게 하여, 가설의 취약점을 입체적으로 파악했습니다.
- Actionable Conclusion: 분석에 그치지 않고, 리서치 리드의 관점에서 비즈니스 방향성을 제안하도록 설계했습니다.
# Task: 도출된 테마 및 사용자 발언 기반 비즈니스 가설 검증
[Hypothesis List]
- 가설 1: [내용 입력]
- 가설 2: [내용 입력]
- 가설 3: [내용 입력]
[Evaluation Criteria]
각 가설에 대해 다음 4가지 요소를 정밀하게 분석할 것:
1. 지지 Evidence: 가설을 뒷받침하는 사용자의 구체적인 발언 및 행동 패턴
2. 반대 Evidence: 가설과 배치되거나 예외적인 케이스의 데이터
3. 해석: 지지/반대 데이터를 종합했을 때 추출되는 핵심 인사이트
4. 결론: 해당 가설의 채택 여부(Accept/Reject/Modify) 및 권장 Action
[Output Format]
- 가설명:
- [지지 Evidence] / [반대 Evidence]
- [해석]
- [결론][Phase 5] 액션 가능한 인사이트
마지막으로 리서치의 진짜 가치는 보고서 그 자체가 아니라,
Product가 어떻게 바뀌어야 하느냐라는 질문에 답하는 데 있습니다.
저는 AI에게 리서치 데이터와 서비스의 도메인 지식을 결합하여
즉시 검토할 수 있는 수준의 Action Items를 도출하도록 요청합니다.
- Domain Context: 주제에 대한 특수한 상황 등을 AI에게 인지시켰습니다.
- Logical Chain: [인사이트] → [실제 발언(증거)] → [심리 해석] → [Action Items]으로 이어지는 논리적 사슬을 구성하여 설득력을 높였습니다.
# Task: [주제] 핵심 인사이트 도출 및 제품 전략 제안
[Analysis Context]
앞선 가설 검증 결과와 태깅된 데이터를 기반으로, 서비스 이용 과정에서 발견된 가장 결정적인 인사이트 3가지를 정리할 것.
[Output Structure]
각 인사이트는 다음 4단계 구조를 엄격히 따를 것:
1. Insight: 사용자가 느끼는 핵심 가치나 결정적인 페인포인트 (한 문장 정의)
2. Evidence: 해당 인사이트를 뒷받침하는 실제 사용자 발언 (Quote)
3. Interpretation: 사용자의 심리적 배경이나 행동의 근본 원인 분석
4. Product Implication: 이를 해결/강화하기 위한 구체적인 제품 기능이나 UX 개선안
[Step 3] 의사결정 최적화: 근거 기반의 구조화된 리포팅
리서치의 가치는 결국 유관 부서를 설득하고
실제 액션으로 이어지게 만드는 데 있습니다.
저는 NotebookLM을 통해 보고서의 전달력을 높입니다.
리서치 결과의 신뢰성은 근거에서 나옵니다. NotebookLM은
제가 업로드한 Raw data 내에서 RAG 기반으로 답변을 생성하는
Grounded Generation 방식을 취하기 때문에
AI가 지어낸 이야기가 아닌 실제 사용자의 목소리에 기반한
슬라이드 구조를 잡는 데 최적의 도구였습니다.
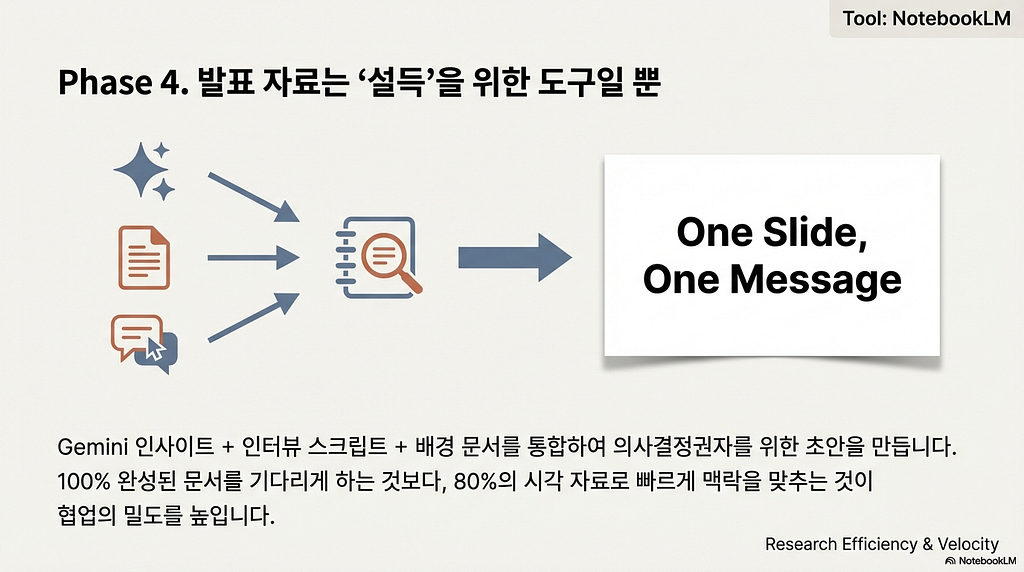
- 다변화된 리포트: 인사이트와 원본 데이터를 학습시킨 뒤,
맥락 중심의 상세 버전과 의사결정권자를 위한
‘One Message’ 슬라이드 구조를 동시에 생성합니다. - 시각적 구조화: 비록 AI가 생성한 이미지나 텍스트에
일부 오탈자가 있더라도, 복잡한 정보를 한눈에 들어오게
시각화하는 것에 우선순위를 둡니다. 조직은 완벽한 문장보다
빠르고 명확한 맥락 공유를 더 필요로 하기 때문입니다.
AI 리서치의 핵심은 한 번의 완벽한 답변을 기대하는 것이 아니라,
여러 번의 변주 속에서 리서처가 최적의 맥락을 골라내는
큐레이션에 있습니다.
많은 분이 AI에게 한 번 질문하고 나온 답변을
그대로 결과물에 사용하곤 합니다.
하지만 저는 NotebookLM을 활용할 때
동일한 자료로 여러 번 뽑는 전략을 사용합니다.
왜 여러 번 뽑아야 할까요?
- 맥락의 재구성: 동일한 Raw date라도 AI가 매번 강조하는 지점이 미세하게 다를 수 있습니다. 이를 반복하면 리서처가 놓쳤던 사소한 맥락이 나타나기도 합니다.
- 결과 교차 검증: 여러 번 생성했을 때 공통으로 등장하는 키워드는 확실한 근거가 있는 핵심 인사이트일 확률이 높습니다.
[Step 4] 리서치 품질 관리: AI 기반 모더레이팅 회고
리서치 결과만큼 중요한 것이 리서처 자신의 태도와 질문의 품질입니다.
저는 AI를 시니어 리서처 페르소나로 설정해
제 인터뷰 스크립트를 객관적으로 평가받습니다.
Prompt Intent
- Self-Objectification: 리서처 본인의 발언을 데이터화하여 분석 대상으로 삼습니다.
- Bias Detection: 자신도 모르게 던진 유도형 질문이나 편향된 추임새를 식별합니다.
# Task: 인터뷰 모더레이팅 품질 리뷰 및 개선안 제안
[Context]
나는 이번 인터뷰를 진행한 모더레이터야. 내가 진행한 인터뷰 스크립트를 학습하고, 다음 관점에서 나에게 피드백을 줘.
[Review Points]
1. 유도형 질문: 답변을 특정 방향으로 유도하거나 '네/아니요'를 강요한 질문이 있는가?
2. 경청 및 심층 탐색: 사용자의 답변 중 추가 질문(Probing)이 필요했는데 놓친 지점은 없는가?
3. 중립성: 사용자의 부정적인 의견에 당황하거나, 긍정적인 답변에만 과하게 반응하지 않았는가?
[Output Format]
- 발견된 문제점: "당시 나의 발언"
- 개선 제안: "다음에 다시 질문한다면 이렇게 물어보세요."
- 총평: 이번 인터뷰 진행의 전반적인 객관성 점수 및 조언
마치며: 대체가 아닌 사고의 확장
리서처에게 AI는 내 자리를 위협하는 대체재가 아니라,
역량을 증폭시키는 가장 유능한 조력자입니다.
기존에는 리서처가 직접 데이터를 정리하고 요약하는 작업자에 가까웠다면
이제는 무엇을 물어야 할지 정의하고, 어떤 가설로 데이터를 볼지 선택하는
맥락의 편집자로 역할이 변화하고 있습니다.
도구가 예리해질수록 그것을 휘두르는 리서처의 감각은
더욱 중요해질 것입니다.
도구를 활용한 효율화는 단순히 업무 시간을 줄이는 것을 넘어
리서처가 더 높은 차원의 전략적 인사이트에 집중할 수 있는
리서치 환경의 확장을 의미합니다.
AI가 바꾸는 UX 리서치: 설계부터 품질 관리까지 was originally published in YOGIYO Tech Blog - 요기요 기술블로그 on Medium, where people are continuing the conversation by highlighting and responding to this story.










 English (US) ·
English (US) · 