들어가며
안녕하세요. LY Corporation의 DBaaS DevOps 팀에서 일하고 있는 박정무입니다.
LY Corporation은 대규모 프라이빗 클라우드를 직접 개발해 운영하고 있으며, 프라이빗 클라우드 환경에서 데이터베이스는 DBaaS(Database as a Service) 형태로 제공합니다. 현재 저희는 구 LINE Corporation에서 사용하던 ‘Verda’와 구 Yahoo Japan Corporation에서 사용하던 ‘YNW’라는 두 거대한 클라우드를 차세대 클라우드인 Flava로 통합해 나가는 과정에 있습니다. 이번 글에서는 Flava DBaaS의 설계와 사양을 소개하고, 마이그레이션 전략과 앞으로 Flava DBaaS가 발전해 나가야 할 방향을 설명하겠습니다.
Flava DBaaS 설계
오퍼레이터 패턴
Flava에서 제공하는 DBaaS는 쿠버네티스에서 작동하는 오퍼레이터 패턴을 기반으로 합니다.
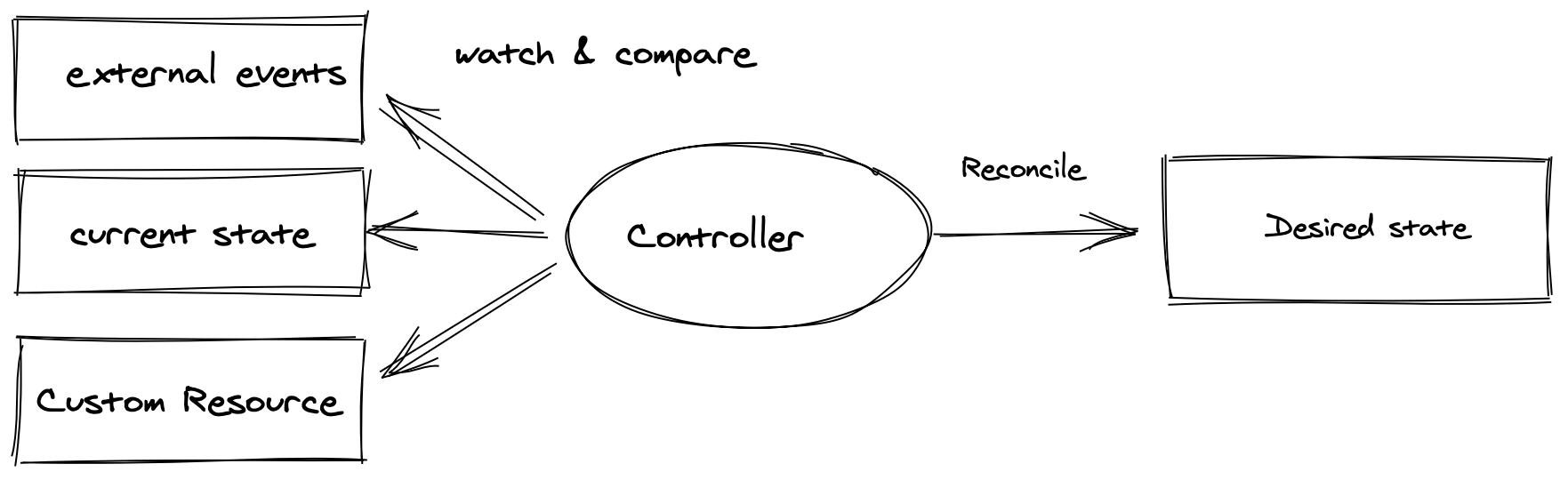 출처: https://github.com/cncf/tag-app-delivery/blob/main/operator-wg/whitepaper/Operator-WhitePaper_v1-0.md, Licensed under the Apache License, Version 2.0.
출처: https://github.com/cncf/tag-app-delivery/blob/main/operator-wg/whitepaper/Operator-WhitePaper_v1-0.md, Licensed under the Apache License, Version 2.0.
오퍼레이터 패턴은 운영자(operator)가 도메인 지식을 기반으로 수행하던 작업을 컨트롤러(controller) 형태의 코드로 만들어 쿠버네티스의 선언적 API 모델을 이용해 자동으로 작동하도록 만드는 설계 방식입니다. 사용자가 ‘이런 상태의 DB가 필요하다’는 의도를 선언하기만 하면 운영자의 도메인 지식을 기반으로 개발된 컨트롤러가 선언한 상태에 도달하기 위한 절차를 지속적으로 수행합니다.
선언 방식으로 작동하는 오퍼레이터 패턴으로 구성한 DBaaS는 개발 구현 난이도는 높지만, 절차 지향적으로 구성한 아키텍처보다 운영하고 관리하기 편합니다. 운영 중 문제가 발생했을 때 선언된 커스텀 리소스의 사양과 상태를 비교하고 컨트롤러의 로그를 확인하는 것만으로 문제가 발생한 원인을 찾을 수 있습니다. 또한 이벤트 기반의 방식으로 작동하는 컨트롤러는 대규모 데이터베이스 인프라 환경에서도 큰 부하 없이 작동합니다. CI/CD 구축 및 운영이나 권한 관리 등에 쿠버네티스 생태계에서 제공하는 여러 기능을 사용할 수 있다는 장점도 있습니다.
IaaS 관리와 인프라 오퍼레이터
DBaaS와 같은 PaaS(Platform as a Service)는 IaaS(Infra as a Service)에서 작동하기 때문에 IaaS를 효율적으로 제어할 수 있게 설계해야 합니다. IaaS에서 데이터베이스 클러스터를 하나 구성하려면 여러 개의 VM, 스토리지, 도메인 등 IaaS 측에서 제공하는 자원을 생성하고 관리해야 합니다. 따라서 DBaaS 수준에서 IaaS를 제어하기 위한 API를 직접 다루는 경우 DBaaS 코드의 많은 부분이 인프라를 제어하는 로직으로 채워지고, DB를 운영하고 관리하기 위한 비즈니스 로직과 인프라 제어 로직이 뒤섞입니다.
이러한 점을 개선하기 위해 Flava DBaaS는 IaaS 자원을 다루는 계층을 별도의 인프라 오퍼레이터(infra operator)로 추상화합니다. 인프라 오퍼레이터는 IaaS 자원을 쿠버네티스 리소스 형태로 다룰 수 있도록 해주는 플랫폼으로, IaaS API 호출을 직접 수행하는 대신 쿠버네티스의 선언적 API 모델을 그대로 인프라 자원에 적용할 수 있게 해 줍니다. 예를 들어, 데이터베이스를 설치할 VM을 생성하려면 먼저 다음과 같이 선언적으로 사용할 server.yaml을 정의합니다.
name: testserver namespace: testnamespace spec: availabilityZone: az3 image: Rocky Linux 8.10 serverType: 4vCPU-8GiB이후 다음과 같이 server.yaml을 통해 커스텀 리소스를 생성합니다.
kubectl create -f server.yaml이와 같이 인프라 오퍼레이터를 이용하면 선언적으로 VM을 생성할 수 있습니다. DBaaS 입장에서는 IaaS 측의 API나 호출 절차를 알 필요 없이 server.yaml에 필요한 사항을 선언하기만 하면 쿠버네티스 리소스만으로 IaaS를 다룰 수 있습니다.
인프라 오퍼레이터를 도입한 Flava DBaaS의 계층 구조는 다음과 같습니다.
+-----------------+ | DBaaS | ← Focus on database business logic +-----------------+ | 인프라 오퍼레이터 | ← Abstracting IaaS as Kubernetes resources +-----------------+ | IaaS | ← Provide compute, network, storage +-----------------+인프라 오퍼레이터를 사용하면 각 계층의 책임이 명확히 분리됩니다. 이를 통해 IaaS에서 제공하는 자원을 여러 DBMS에서 같은 방식으로 다룰 수 있으며, 각 DBaaS 상품 개발자는 DBMS에 종속된 비즈니스 로직에 집중할 수 있습니다.
커스텀 리소스와 API 서버, 매니저, 에이전트
인프라 오퍼레이터에서 IaaS 리소스를 커스텀 리소스 형태로 표현하듯, 각 DBMS에서는 데이터베이스 클러스터를 다음과 같은 하나의 커스텀 리소스로 표현합니다.
name: testmysql namespace: testnamespace spec: version: mysql-8.0.45 serverType: Cx.4vCPU_16GiB_100GiB storage: type: nvme_dev size: 200GiB replication: member: 1이 커스텀 리소스는 사용자가 원하는 상태의 데이터베이스를 표현하고 있습니다. 프라이머리를 복제하는 멤버를 1개 구성하고, VM의 스펙은 4 vCPU, 16GiB 메모리, 100GiB 디스크를 사용하며, 별도로 200GiB 블록 스토리지를 사용합니다. 커스텀 리소스는 YAML 형태로 쿠버네티스 etcd에 저장되며, 쿠버네티스에서 제공하는 API를 이용해 조회, 생성, 수정, 삭제할 수 있습니다.
DBaaS는 이러한 커스텀 리소스를 참조하는 세 개의 컴포넌트로 구성되어 있습니다.
- API 서버: 사용자에게 제공하는 기능을 사용하는 방식을 제공하는 REST API입니다. 선언적으로 정의한 커스텀 리소스를 생성, 수정, 삭제하는 역할을 담당합니다. Flava UI 혹은 IaC(Infrastructure as Code) 도구에서는 해당 API를 호출합니다.
- 매니저: 커스텀 리소스 변경 사항에 맞춰 사양과 상태가 일치하도록 지속적으로 조정(reconcile)하는 컨트롤러 프로세스입니다. 데이터베이스 클러스터의 현재 상태를 확인하고 명령을 수행하는 등의 작업을 총괄합니다.
- 에이전트: 데이터베이스 프로세스가 실행되는 VM에서 함께 실행되며, 커스텀 리소스 변경 사항에 맞춰 운영체제나 데이터베이스 등에서 수행해야 하는 명령을 수행하는 프로세스입니다. 로컬에서만 작동하는 명령을 수행하거나, 프로비저닝 등의 로직에 깊게 관여합니다.
커스텀 리소스와 API 서버, 매니저, 에이전트가 어떻게 작동하는지 MySQL 클러스터를 생성하는 시나리오를 가정한 예시와 함께 살펴보겠습니다.
사용자가 본인이 구성하고 싶은 데이터베이스 클러스터의 정보를 담아 API를 호출하면, API 서버가 사용자의 요청에 맞는 MySQL 커스텀 리소스를 생성합니다. 이를 통해 복제 구성이나 MySQL을 구성하는 서버 사양 등 MySQL 클러스터를 구성하기 위해 필요한 정보가 커스텀 리소스 사양에 기록되고, 쿠버네티스 etcd에 저장됩니다.
API Server -> kubectl create mysqlservice -f mysqlservice.yaml - mysqlservice.yaml name: testmysql namespace: testnamespace spec: version: mysql-8.0.45 serverType: Cx.4vCPU_16GiB_100GiB storage: type: nvme_dev size: 200GiB replication: member: 1매니저는 생성된 커스텀 리소스의 생성과 변화를 감지하고 커스텀 리소스 사양에 정의된 상태와 맞추기 위한 명령들을 수행하기 시작합니다. 사양에 정의된 VM을 생성하기 위해 인프라 오퍼레이터에서 제공하는 서버라는 커스텀 리소스를 생성하고, VM 생성이 완료된 후 에이전트가 복제를 구성하기 위한 복제 명령을 수행하도록 합니다.
에이전트는 VM 생성 시 VM 내부에 설치되어 작동하며, 커스텀 리소스 사양을 확인하고 이 상태에 도달하기 위해 OS 명령 또는 데이터베이스 명령을 수행합니다.
이와 같이 각 DBMS는 API 서버와 매니저, 에이전트의 세 개 컴포넌트로 분리 구성하며, 이를 통해 각 프로세스의 역할을 명확하게 분리할 수 있습니다.
Flava DBaaS에서 개선한 점
DBaaS에서는 플랫폼 차원에서 프로비저닝, 고가용성(high availability), 백업과 복구, 확장성(scalability), 모니터링 등의 기본 기능을 제공해야 합니다. 기존에 사용하던 Verda나 YNW와 같은 클라우드 서비스에서도 이와 같은 기능을 제공하고 있었으며, Flava 역시 제공하고 있습니다. 또한 이에 더해 기존에 많은 개발자가 요구했던 사항을 개선 제공하기 위해 노력했습니다. 어떤 점들을 개선했는지 하나씩 살펴보겠습니다.
지원하는 DBMS 종류 확대
Flava에서는 기존 Verda와 YNW에서 제공하던 DBMS를 통합해 더욱 많은 DBMS를 제공하고 있습니다.
지원 기능 추가
기존 클라우드 서비스에서 진행한 사용자 만족도 조사 결과를 기반으로 Flava DBaaS에 새로운 기능을 추가했습니다.
더욱 유연한 확장성
사용자는 필요에 따라 100GiB 단위로 유연하게 스토리지를 구성할 수 있습니다. 또한 블록 스토리지를 사용하는 DBMS에서는 사용할 수 있는 스토리지 용량을 최대 5TiB까지 늘렸습니다.
기존 클라우드에서는 VM의 로컬 디스크를 사용했기 때문에 DBMS에서 제공하는 스토리지의 용량이 하이퍼바이저에서 제공하는 VM의 스펙에 종속되었습니다. 하지만 Flava에서는 VM을 생성할 때 사용자 정의 인스턴스 유형을 지원하고, DBMS에서 블록 스토리지를 사용하면서 스토리지 구성이 유연해졌으며, 스토리지 최대 크기도 5TiB까지 늘어났습니다. 블록 스토리지 자체는 5TiB 이상으로 사용할 수 있었지만 기존 클라우드의 사용 사례를 분석한 결과 5TiB로 대부분의 요구 사항을 커버할 수 있었으며, 블록 스토리지 측의 서버 단편화를 방지하기 위해서 최대 크기를 5TiB로 결정했습니다.
기존 클라우드에서는 단일 VM의 스토리지 용량 한계 때문에 샤딩 같은 대안을 검토해야 하는 경우가 있었습니다. Flava DBaaS에서는 최대 스토리지 용량이 늘었기 때문에 그러한 검토가 필요하지 않을 수 있습니다.
통일된 사용자 경험 제공
Flava에서 제공하는 DBaaS는 모두 통일된 아키텍처와 UI를 기반으로 통일된 사용자 경험을 제공합니다. 사용자는 DBMS별로 다른 방식으로 DBaaS를 제어할 필요가 없습니다. 예를 들어 MySQL에서 서버 사양을 변경했다면 그 경험을 기반으로 Redis의 서버 사양도 변경할 수 있습니다. 또한 Cassandra의 모니터링 알람을 설정한 경험을 기반으로 MySQL의 모니터링 알람도 설정할 수 있습니다. 동일한 UI와 UX를 제공하기 때문에 사용자는 DBMS별로 사용 방법을 따로 배울 필요가 없습니다.
보안 기능 강화
Flava에서 제공하는 DBaaS는 기본적으로 TDE(transparent data encryption)와 TLS(transport layer security) 같은 보안 기능을 DBaaS 차원에서 제공합니다.
편의 기능 추가
Flava DBaaS에서는 사용자 경험을 개선하기 위해 여러 가지 편의 기능을 제공하고 있습니다.
- ‘Custom DB Role’ 기능: 사용자는 자신이 원하는 수준의 권한이 부여된 데이터베이스 사용자를 유연하게 생성 및 관리할 수 있고, 재사용할 수도 있습니다.
- ‘Database Parameter Group’ 기능: 원하는 데이터베이스 파라미터를 제어할 수 있으며, 이를 재사용할 수 있습니다.
- ‘Restore backup’ 기능: 특정 백업을 기반으로 신규 데이터베이스 클러스터를 생성할 수 있습니다. 이 기능을 이용하면 장애 발생 시 백업을 기반으로 복구하거나, 성능 테스트 등을 위해 실제 환경과 동일한 데이터가 적재된 데이터베이스가 필요한 경우 UI에서 빠르게 복구할 수 있습니다.
아직 위 기능을 제공하지 않는 DBaaS에서도 위 기능을 제공하기 위해 준비하고 있습니다.
기존 클라우드 서비스 운영 과정에서 받은 사용자 의견을 기반으로 Flava에서는 더 좋은 DBaaS를 제공하기 위해 여러 기능을 개선했고, 그 결과 사내 사용자 만족도 조사에서 높은 점수를 받았습니다.
마이그레이션까지 DBaaS의 역할
신규 DBaaS를 개발해 사용자에게 제공하는 것만으로 DBaaS의 역할이 끝나는 것은 아닙니다. 기존 플랫폼에서 쉽고 간편하게 마이그레이션할 수 있는 방법을 제공하는 것까지가 신규 DBaaS 플랫폼이 담당해야 할 몫입니다. 기존 플랫폼에서 Flava DBaaS로 마이그레이션할 수 있는 방안을 제공하기 위해 어떤 노력을 하고 있는지 설명하겠습니다.
같은 DBMS 간 마이그레이션 방법
Flava DBaaS에서 제공하는 방법을 살펴보기에 앞서, 같은 DBMS 간에 마이그레이션하는 방법을 살펴보겠습니다. 동기종 DBMS 사이에서 마이그레이션하는 방식은 크게 세 가지입니다.
덤프 & 복구(dump & restore)
소스 데이터베이스에서 백업을 수행한 뒤 목적지 데이터베이스에 복구를 수행합니다. 가장 간단한 마이그레이션 방식이지만 데이터 정합성을 보장하기 위해서는 애플리케이션을 중단해야 합니다.
복제(replication)
DBMS 자체에서 제공하는 복제 메커니즘을 이용하는 방식입니다. 먼저 소스 데이터베이스에서 목적지 데이터베이스로 향하는 실시간 복제를 구성한 뒤, 실시간 복제가 완료되면 페일오버(failover)를 통해 프라이머리의 노드를 목적지 데이터베이스 쪽으로 변경하고 소스 데이터베이스를 제거하는 방식입니다.
이 방식에서 데이터 정합성은 DBMS 자체에서 제공하는 복제 메커니즘에 의존합니다. 또한 프라이머리 노드의 페일오버 시점에 최소한의 애플리케이션 중단이 발생할 수 있으며, 페일오버 전에 애플리케이션에서 사용하는 데이터베이스 엔드포인트 등을 변경하는 작업이 필요하기 때문에 덤프 & 복구 방식에 비해 상대적으로 절차가 복잡하고 오래 걸릴 수 있습니다. 보통 무중단으로 마이그레이션하고자 할 때 가장 많이 선택하는 방법입니다.
변경 데이터 캡처(change data capture)
Kafka와 같은 별도 시스템을 구축해 데이터베이스 간 데이터를 논리적으로 복사하는 방식입니다. 논리적 마이그레이션이기 때문에 동기종 마이그레이션이라고 하더라도 토폴로지의 한계를 뛰어넘을 수 있습니다. 예를 들어, 6개 샤드로 구성된 Redis 클러스터를 3개의 샤드로 구성된 Redis 클러스터로 마이그레이션할 수 있습니다. 별도 시스템을 구축하고 운영 및 관리해야 하기 때문에 복잡도가 증가하지만 무중단에 가깝게 마이그레이션할 수 있습니다.
Flava DBaaS에서 제공하는 마이그레이션 도구
마이그레이션은 데이터베이스를 운영하는 운영자와 사용하는 개발자가 긴밀히 협업하며 진행하는 작업입니다. 대규모 데이터베이스를 운영 및 관리하는 운영자가 혼자 전부 마이그레이션하는 것은 불가능에 가깝기 때문입니다. 최선의 방식은 데이터베이스를 사용하는 개발자가 별도 지식 없이도 쉽고 간편하게 마이그레이션할 수 있도록 완성도 높은 도구와 매뉴얼을 제공하는 것입니다.
현재는 MySQL에 대해서만 DMB(data migration bridge)라는 이름으로 개발자가 직접 사용할 수 있는 마이그레이션 도구를 제공하고 있는데요. 2026년 2분기까지 Flava에서 제공하는 모든 DBMS을 대상으로 개발자가 직접 사용할 수 있는 형태의 마이그레이션 도구를 제공하는 것이 목표입니다. DBMS별로 워크로드와 특성이 다르기 때문에 마이그레이션 도구에서 제공하는 방식이 각 DBMS별로 다를 수는 있지만, 사용자가 마이그레이션하기 위한 도메인 지식 없이 UI 지시를 따르는 것만으로 쉽고 간편하게 마이그레이션할 수 있게 만드는 것이 공통 목표입니다.
Flava DBaaS의 미래
지금까지 현재 Flava DBaaS의 모습을 소개했습니다. 이제 시선을 한발 앞으로 옮겨 내일의 Flava DBaaS가 어떠할지 살펴보겠습니다.
기존 클라우드 서비스에서 제공하던 DBMS 지원
기존 YNW에서 제공하던 Fractal DB나, DBA 지원을 통해서 이용하던 HBase 등의 데이터베이스도 DBaaS 형태로 제공할 수 있도록 준비하고 있습니다.
보안 환경 지원
LY Corporation은 사회 인프라로서 서비스를 제공하고 있기 때문에 엄격한 보안 수준을 유지하는 것 등이 필요합니다. Flava DBaaS도 이런 요구 사항에 맞춰 기능을 제공할 것을 요구받고 있습니다.
Flava는 사내의 엄격한 데이터 거버넌스 및 보안 기준에 따라 데이터를 보안 등급별로 격리해 저장 및 처리하는 아키텍처로 설계했습니다. Flava DBaaS도 마찬가지로 취급하는 데이터의 중요도와 성질에 따라 고도의 분리 관리 환경을 단계적으로 확충하고 적용해 나가고 있습니다. 보안을 엄격하게 갖춘 후 그다음으로 중요한 것은 사용성입니다. Flava DBaaS에서는 데이터의 보안 등급에 따라서 사용성이 달라지지 않고 모든 보안 등급에서 빠르고 편리하게 데이터베이스 환경을 구축할 수 있도록 준비하고 있습니다.
서버리스 DBaaS
독립적인 데이터베이스 클러스터 형태로 제공되는 DBaaS는 안정적인 데이터베이스 운영 환경을 제공할 수 있지만 플랫폼 전체 관점에서는 독립적인 이중화 등의 이유로 자연스럽게 리소스 활용률이 낮아집니다. Flava DBaaS는 이러한 문제를 해결하기 위해 서버리스 DBaaS를 준비하고 있습니다.
서버리스 DBaaS는 여러 사용자가 멀티 테넌트 형태로 공통 인프라를 효율적으로 사용할 수 있도록 설계합니다. DBaaS 운영자는 전체적인 관점에서 리소스 활용률을 높히고 버전 업그레이드나 백업과 같은 운영 작업을 표준화하여 운영 비용을 낮출 수 있습니다. 사용자는 클러스터 구성이나 서버 사양 등을 고민할 필요 없이 필요한 리소스를 즉시 자유롭게 사용하며, 비용은 사용한 만큼만 청구됩니다. 서버리스 DBaaS에서는 잘 알려진 시끄러운 이웃(noisy neighbor) 등의 문제가 발생할 수 있는데요. 이를 해결하기 위해 테넌트 간 리소스 격리 등도 도입해 검증하고 있습니다.
서버리스 DBaaS가 모든 워크로드에서 적합한 것은 아닙니다. 높은 수준의 성능이나 전용 인프라 구성이 필요한 워크로드의 경우 독립적인 클러스터 기반의 DBaaS가 더 적합합니다. Flava DBaaS는 워크로드 특성에 따라 서버리스 DBaaS와 전용 클러스터 기반 서비스를 함께 제공하여 다양한 요구 사항을 수용할 계획입니다.
현재는 우선적으로 MySQL 호환의 TiDB 서버리스 데이터베이스와 서버리스 검색(Serverless Opensearch)를 준비하고 있습니다. 이를 통해 증가하는 데이터베이스 수요를 적극적으로 수용하며 인프라 리소스를 효율적으로 사용할 수 있는 방법을 고민하고 있습니다.
인텔리전트 DBaaS
Flava DBaaS가 AI 시대에 맞춰 나아가야 할 방향 중 가장 도전적인 방향은 인텔리전트 클라우드(intelligent cloud)입니다.
DBA as a Service
DBA는 오랫동안 DB 운영의 핵심을 책임져왔습니다. 알람 발생 시 원인을 찾아 대응하고, 느린 쿼리를 분석해 튜닝하고, 사용자에게 적절한 운영 가이드를 제공하는 등 안정적으로 작동하는 데이터베이스의 뒷면에는 언제나 DBA 가 있었습니다. DBA as a Service는 이러한 DBA의 역할을 AI 에이전트 형태로 제공하는 것입니다.
사용자는 DBA와 소통하면서 받았던 상담 등을 Slack 봇을 통해서 서비스 형태로 받을 수 있습니다.
- 알람 분석: 알람 발생 시 지표와 로그를 분석해 현재 발생한 알람의 원인을 파악한 뒤 검증한 결과를 기반으로 대응 제안을 제시합니다.
- 이슈 대응: "13:05분 부터 db-prod-01의 쿼리 지연 시간이 증가했는데 왜 그런거야?"라고 질문하면 Slack 봇이 지표와 로그를 조회한 뒤 답변해 줍니다. 답변 후 후속 질문에도 적절히 답변해 주기 때문에 마치 DBA와 소통하는 것처럼 이슈 원인을 분석할 수 있습니다.
- 문의 대응: 데이터베이스 사양 산정, 클러스터 구성 선정, 백업 정책 설정 등과 관련된 조언을 제공합니다. 예상 QPS나 데이터 크기 등의 정보, 데이터의 성격, 서비스 개요 등을 제공하면 적절한 구성을 제안합니다.
Slack 봇뿐 아니라 Flava 콘솔(웹 UI)에서 리포트 탭도 제공합니다. 리포트 탭에서는 DBaaS를 더 잘 사용할 수 있는 개선 제안을 리포트 형태로 받을 수 있습니다.
- 일단위, 또는 특정 시간 단위의 DB 사용 패턴을 확인하여 백업 시간이 배치 시점과 겹친다면 백업 시간 변경을 추천하거나, 리소스 사용률을 확인하고 리소스 절감 가능 여부를 판단하여 제안합니다.
- 느린 쿼리의 패턴을 분석해 쿼리 튜닝 방식을 제안하거나 적절한 인덱스를 추천합니다.
- 저장돼 있는 데이터 중 개인정보로 판단되는 정보가 있다면 보고 후 암호화를 제안합니다.
오토 스케일링
DBMS 리소스를 어떻게 하면 보다 효율적으로 사용할 수 있을지는 모든 운영자가 항상 고민하는 부분입니다. 리소스를 과도하게 할당하면 비용이 낭비되고, 부족하게 할당하면 성능이 저하되고 장애를 유발할 수 있기 때문입니다.
Flava DBaaS는 이 문제를 해결하기 위해 오토 스케일링 기능을 제공하고자 합니다. 사용자는 CPU, 메모리, 스토리지, 커넥션 등의 지표를 기반으로 정책을 설정할 수 있으며, 정책을 기반으로 필요한 리소스를 자동으로 확장하거나 축소합니다. 예를 들어 새벽 시간에 대규모 배치 작업이 예정되어 있는 경우 DBaaS는 사전에 읽기 복제를 생성해 읽기 부하를 분산하고 작업이 종료된 이후에는 읽기 복제를 반납해 비용을 최적화합니다. 또 다른 예시로는, 데이터가 증가해 디스크 사용률이 임계치에 도달한 경우 스토리지를 20% 증가시킨 노드로 VM 사양을 변경할 수 있습니다.
이런 오토 스케일링 기능을 DBA as a Service와 연계한다면 더욱 지능적이고 안정적인 오토 스케일링 기능을 제공할 수 있을 것입니다. AI 에이전트는 데이터베이스 사용 패턴과 리소스 사용 이력을 분석해 현재 설정된 오토 스케일링 정책이 적절한지 검토하고 개선 방안을 제안할 수 있을 것입니다. 예를 들어 특정 시간대에 반복적으로 발생하는 트래픽 증가 패턴을 분석해 오토 스케일링 임계치 조정을 권장하거나, 데이터 증가 추세를 바탕으로 사전 증설 정책을 제안할 수 있습니다. 이를 통해 사용자는 복잡한 정책 설계를 고민할 필요 없이 리소스가 효율적으로 사용되는 것을 경험할 수 있습니다.
마치며
지금까지 Flava DBaaS의 아키텍처와 사양, 기존 플랫폼에서의 마이그레이션하기 위해 제공하는 도구, 앞으로 Flava DBaaS가 발전해 나갈 모습까지 살펴봤습니다. Flava DBaaS는 기존 플랫폼을 운영해 본 경험을 기반으로 더 개선된 형태로 안정적이고 편안한 DBaaS를 제공하기 위해 노력하고 있으며, AI 시대에 발 맞춰 DBaaS를 어떻게 제공해야 할지 답을 찾아가고 있습니다.
앞으로 Flava DBaaS가 만들어 낼 변화에 많은 관심 부탁드립니다. 긴 글 읽어주셔서 감사합니다.
Tech-Verse 2026 개최 안내 — 6월 29일

이 글은 이벤트의 공식 기사로 공개되었습니다.
Tech-Verse 2026은 LY Corporation가 개최하는 기술 컨퍼런스입니다.
혁신적인 기술적 도전 과정과 현장의 생생한 인사이트를 공유합니다.
YouTube LIVE를 통한 생중계도 꼭 시청해 주세요.
https://tech-verse.lycorp.co.jp/2026/ko/









![[G-브리핑] 컴투스, 임직원 참여형 ESG 플로깅 활동](https://pimg.mk.co.kr/news/cms/202606/11/news-p.v1.20260611.0f1bb9233318459cb7ad7f04a40a2d5c_R.jpg)



 English (US) ·
English (US) · 