대규모 언어 모델(large language model, 이하 LLM)의 물리적 입력 한계가 수백만 토큰으로 확장되면서 소프트웨어 엔지니어링 업계에는 더 큰 컨텍스트 창(context window)이 더 높은 운영 지능을 의미한다는 전제가 널리 퍼져 있습니다. 그러나 자동 코드 리팩토링, 지속적인 코드 리뷰, 장기 소프트웨어 개발 루프와 같은 프로덕션급 에이전트형 워크플로에서 큰 컨텍스트 창에 수동적으로 토큰을 채워넣는 '토큰 스터핑(token stuffing)' 방식에 의존하면 심각한 실패를 마주할 수 있습니다. 능동적인 런타임 거버넌스(runtime governance)가 없으면 멀티헤드 어텐션 메커니즘은 정보 엔트로피가 축적되면서 추론 능력이 저하되고, 컨텍스트가 부패하며(context rot), 중요한 데이터를 유출할 수 있는 취약점을 노출할 것입니다.
이 글에서는 시맨틱 컨텍스트 OS 아키텍처를 소개합니다. 시맨틱 컨텍스트 OS 아키텍처는 컨텍스트 창을 ‘관리하지 않는 텍스트 스트림’에서 ‘결정론적 시스템 자원’으로 변환하기 위해 설계한, 로컬에서 고속으로 작동하는 인지적 런타임 기반 계층(cognitive runtime substrate)입니다. 시맨틱 컨텍스트 OS는 AI 에이전트 애플리케이션 로직과 외부 파운데이션 API 사이에서 인터셉팅 루프백 프록시(localhost:8080)로 작동하며 AI 전용 커널 역할을 수행합니다. 이 커널의 특징은 다음과 같습니다.
- POSIX와 유사한 VFS(virtual file system)를 이용해 상태 토폴로지 관리
- 자체 개발한 ‘PathAlign 단계’를 통해 AST(abstract syntax tree) 트리 가지치기 적용
- 자체 개발한 비동기 방식의 톱니(sawtooth) 메모리 모델을 사용해 실행 중 토큰 최적화 수행
시맨틱 컨텍스트 OS는 정량적인 하드웨어 수준의 토큰 한계와 정성적인 시맨틱 거버넌스를 명확히 분리함으로써 다운스트림 추론 엔진을 구조적 잡음으로부터 보호하고 기업의 지적 재산권을 안전하게 지킵니다. 궁극적으로 이 프레임워크는 엔터프라이즈 규모에서 견고하고 안전하며 비용 효율적인 자율 소프트웨어 엔지니어링 에이전트를 설계하기 위한 성숙하고 재현 가능한 표준을 확립합니다.
면책 고지 사항: 이 글에서 소개하고 사용하는 ‘시맨틱 컨텍스트 OS’라는 명칭은 에이전트 기반 워크플로에서 LLM 어텐션 거버넌스 및 토큰 생애 주기를 관리하기 위해 저자들이 자체적으로 설계한 사내 독점적 런타임 기반만을 가리킵니다. ElixirData Context OS와 같이 유사한 명칭을 가진 상업적 데이터 통합 플랫폼과 어떠한 관계나 아키텍처 관점의 연관성, 상표 관련 제휴는 없습니다.컨텍스트 창은 램이 아니다: 컨텍스트 창 크기의 역설
Karpathy 은유: LLM 메모리 역학 해석
현대 소프트웨어 및 분산 시스템 아키텍처에서 유추적 사고는 복잡하고 비결정론적인 컴퓨팅 패러다임을 이해할 수 있는 좋은 개념적 다리를 제공합니다. 그 중 가장 기초적인 사고 프레임워크 중 하나가 Karpathy 은유이며, Karpathy 은유에서는 전통적인 폰 노이만 컴퓨팅 아키텍처와 LLM 실행 루프가 다음과 같이 구조적으로 대응한다고 이야기합니다.
-
LLM은 CPU처럼 작동한다: LLM은 본질적으로 상태를 갖지 않는 비결정론적 추론 엔진이며, 사전 학습된 파라미터 가중치 안에 내재된 구조적 시맨틱 패턴을 바탕으로 복잡한 수학적 명령 집합을 실행하도록 설계돼 있다.
-
컨텍스트 창은 램처럼 작동한다: 컨텍스트 창은 현재 실행 상태, 과거 텔레메트리, 동적 지시사항, 런타임 운영 데이터가 존재해야 하는 휘발성 작업 메모리 공간이다. 코어 프로세서는 컨텍스트 창을 통해 논리 흐름과 상태 연속성을 유지할 수 있다.
이와 같은 은유가 시스템을 이해하는 데 도움을 주기는 하지만 우리는 소프트웨어 엔지니어로서 이 은유가 근본적으로 깨지는 정확한 경계도 인식해야 합니다.
전통적인 컴퓨팅 공학에서 물리적 실리콘으로 만든 램은 엄격하고 결정론적이며 선형 주소 체계를 기반으로 작동합니다. 만약 저수준 포인터가 0x7FFF와 같은 특정 메모리 주소를 참조하면, 운영체제는 그 정확한 좌표에 저장된 바이트를 O(1) 시간 복잡도와 100% 정밀도로 가져옵니다. 이 작동은 시스템을 8GB, 64GB, 128GB 중 어떤 하드웨어 메모리에서 실행하든 완벽히 동일하게 유지됩니다.
반면 LLM의 맥락적 램은 본질적으로 확률적이고 비선형적입니다. LLM은 전적으로 어텐션 메커니즘, 즉 Q, K, V 행렬에 의존하며, 모든 입력 토큰은 시퀀스 내의 다른 모든 토큰에 대해 조밀한 어텐션 점수를 계산해야 합니다. LLM에서 메모리 검색은 주소 조회가 아닙니다. 상대적 가중치의 동적 통계 분포입니다. 따라서 컨텍스트 창의 물리적 용량을 32K 토큰에서 1M 또는 2M 토큰으로 확장한다고 해서 접근 정밀도가 선형적으로 보장되는 것은 아닙니다. 오히려 계산 표면적이 기하급수적으로 확장되면서 시스템적 잡음이 발생하고 구조적으로 성능이 저하되며 아키텍처 관점에서 취약점이 발생합니다.
어텐션 희석이라는 함정: 거대한 컨텍스트의 구조적 실패
현재 AI 업계는 입력 용량이 커지면 운영 지능이 더 높아진다는 가정 하에 무차별적으로 컨텍스트 창을 확장하려는 엔지니어링 경쟁에 갇혀 있습니다. 이 접근법은 트랜스포머 아키텍처의 깊은 핵심에 내재된 중요한 수학적 현실을 간과합니다. 바로 ‘어텐션 희석(attention dilution)’ 함정입니다.
이 실패 상태를 해부하려면 멀티헤드 어텐션의 핵심 수학 연산을 살펴봐야 합니다. 쿼리(Q), 키(K), 값(V)이 주어질 때, 크기 조정 내적 어텐션 점수(scaled dot-product attention score)는 다음과 같이 표현합니다.
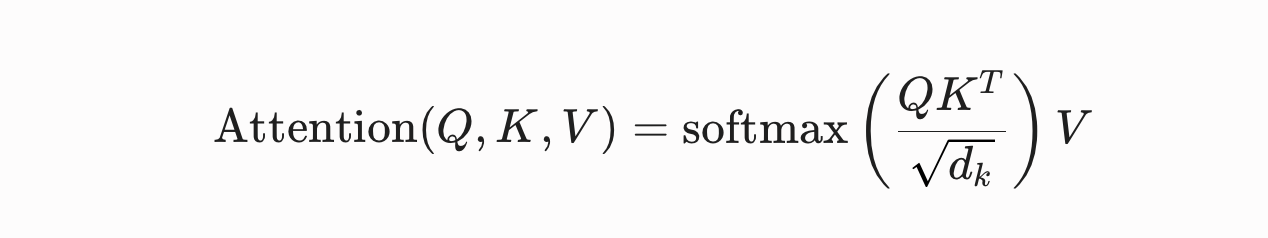
긴 컨텍스트 확장에서 발생하는 수학적 취약성은 단순히 소프트맥스(softmax) 분모가 선형적으로 평탄화되는 데에서 비롯되는 것이 아닙니다. 더 정확히는 내적 행렬(QKT) 내부에서 정보 엔트로피가 축적된 결과입니다. 기업의 코드베이스나 대규모 시스템 로그에는 시퀀스 길이(N)가 커질수록 페이로드 안에 막대한 구조적 잡음이 유입됩니다. 예를 들어 보일러플레이트 정의, 참조되지 않는 import, 중복 구문 토큰 등이 유입됩니다.
그 결과 키 행렬(K)은 쿼리(Q)와 낮은 진폭의 균일한 시맨틱 유사성을 갖는 배경 벡터로 가득 찹니다. 이러한 상황에서 QKT의 내적을 계산하면 고차원 잡음은 분산이 낮은 균일한 어텐션 로짓(attention logit) 분포를 생성합니다. 이 값들이 소프트맥스 지수 함수에 입력되면 어텐션 에너지가 수학적으로 매우 긴 시퀀스 전반에 걸쳐 분산될 수밖에 없습니다. 이러한 구조적 분산은 어텐션 희석 현상을 초래합니다. 즉 정확한 사실 검색과 회수에 필요한 날카로운 어텐션 피크(sharp attention spikes), 다시 말해 뾰족한 델타 분포(sharp delta distributions)가 무뎌지면서 엔트로피가 높은 균일 분포에 가까운 형태로 변질됩니다.
 이미지 생성: 생성형 AI
이미지 생성: 생성형 AI
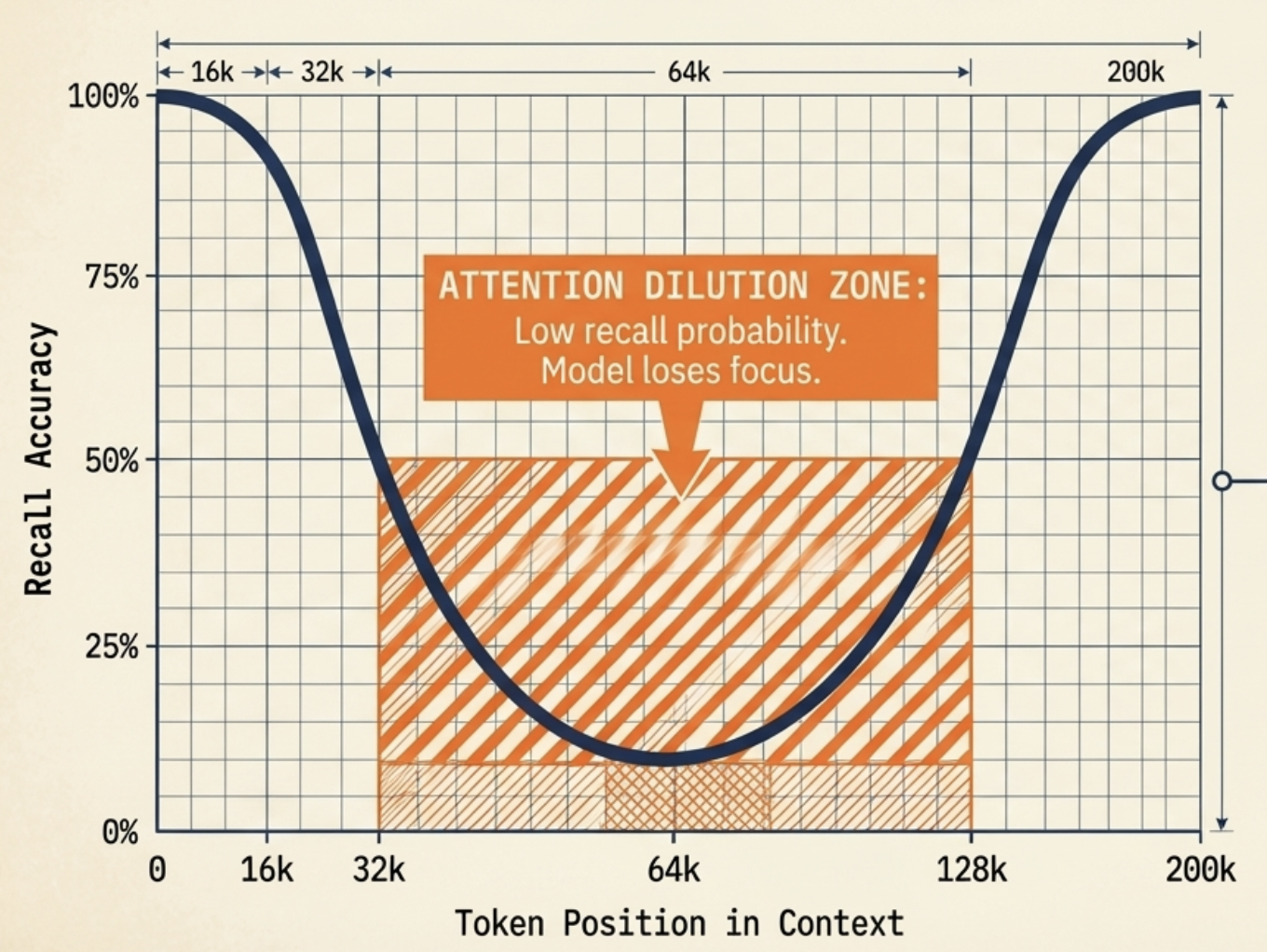
이 수학적 희석은 잘 알려진 ‘중간 정보 유실(lost in the middle)’ 현상(Stanford 대학의 Liu 등이 발표한 Lost in the Middle: How Language Models Use Long Context, Liu et al., 2023에서 U자형 검색 정확도 곡선을 통해 독립적인 현상으로 식별하고 실증적으로 확인된 현상)입니다. LLM은 페이로드의 맨 앞에 위치한 정보, 즉 초두 효과가 적용되는 영역이나 맨 끝에 위치한 정보, 즉 최신성 효과가 적용하는 영역은 비교적 안정적으로 검색할 수 있지만, 컨텍스트 창의 중간 70% 구간에서는 구조적 검색 정확도가 급격히 떨어집니다. 이는 수만 줄의 코드를 검토하거나 서비스 간 의존성 그래프를 추적하는 등 복잡한 소프트웨어 개발 생명 주기 자동화를 담당해야 하는 엔터프라이즈급 AI 에이전트에게는 용납할 수 없는 오차 범위입니다. 능동적인 오케스트레이션 계층 없이 대규모 컨텍스트 창에 의존하는 것은 아키텍처 관점에서 안티 패턴이며, 결국 추론 성능 저하와 심각한 논리적 실패로 이어질 것입니다.
긴 작업 시 발생하는 컨텍스트 부패 현상
AI 에이전트를 자동 엔터프라이즈 코드 리팩토링, 레거시 마이그레이션, 서비스 간 API 계약 검증과 같은 복잡한 장기 작업에 투입하면 컨텍스트 창의 상태는 시간이 지나면서 필연적으로 악화됩니다. 이런 시스템 차원에서의 부패를 ‘컨텍스트 부패(context rot)’라고 정의합니다. 저희는 런타임 관찰가능성 추적을 통한 실증적 관찰을 바탕으로 컨텍스트 부패를 구성하는 세 가지 아키텍처 현상을 식별했습니다.

-
컨텍스트 오염(context poisoning): 다중 턴 자율 실행 루프 동안 에이전트는 과거 미가공(raw) 데이터, 시스템 실행 로그, 오래된 터미널 오류 메시지를 지속적으로 컨텍스트 창에 추가합니다. 이러한 미가공 데이터 축적은 어텐션 행렬을 왜곡합니다. 모델은 일시적인 과거 실패를 현재 작업에 실제로 영향을 끼치는 구조적 제약으로 취급하기 시작하고 그 결과 현재 작업에 유효한 다음 토큰 분포를 생성하는 능력이 오염됩니다.
-
컨텍스트 산만(context distraction): 대규모 기업 모노레포에서는 동일한 명명 규칙, 오버로드된 메서드, 중복된 보조 유틸리티가 서로 완전히 다른 모듈 곳곳에 자주 등장합니다. 표준 검색 메커니즘이 이처럼 관련 없는 코드 조각들을 컨텍스트 창에 쏟아 넣으면 어텐션 메커니즘은 구조적으로 산만해집니다. 그 결과 에이전트는 핵심 대상 로직과 구조적으로 비슷하지만 논리적으로 무관한 코드 블록을 구분하지 못해 핵심 실행 경로를 놓칩니다.
-
컨텍스트 충돌(context clash): AI 에이전트가 다단계 실행 계획을 반복할 때 내부 프롬프트 상태도 함께 진화해야 합니다. 시스템이 이전 단계의 오래된 지시 사항을 지우거나 업데이트하지 못하면 컨텍스트 창은 서로 모순되는 지시사항을 동시에 담게 됩니다(예: ‘1단계: 핵심 DB 인터페이스를 분리하라’와 ‘5단계: 구체적인 구현체를 병합하라’). 그렇게 되면 에이전트는 논리적으로 마비되거나 무한 추론 루프 상태에 빠지며, 이 때문에 멈추거나 타임아웃되거나 환각을 일으킬 수 있습니다.
통계적 텔레메트리는 능동적인 관리 계층이 없으면 에이전트 실패율이 컨텍스트 깊이에 따라 비선형적으로 증가하며, 깊이 중첩된 코드베이스 구조를 만날 경우 실패율이 약 40%에 달할 수 있음을 시사합니다. 이 현실은 수동적인 프롬프트 밀어넣기를 넘어 컨텍스트 환경을 관리할 수 있는 전용 운영체제를 구축해야 할 필요가 있다는 것을 의미합니다.
아키텍처로의 연결: 컨텍스트 부패가 초래하는 시스템적 성능 저하와 어텐션 희석이라는 수학적 현실은, 수동적인 컨텍스트 누적이 자율 에이전트에게 구조적으로 막다른 길임을 보여준다. 이러한 비결정적 실패 상태를 해결하려면 근본적인 아키텍처 패러다임 전환이 필요하다. 즉, 수동적인 프롬프트 엔지니어링에서 능동적이고 경계가 설정된 거버넌스 계층으로 전환해야 한다. 다음 섹션에서는 이 원칙을 강제하도록 설계된 핵심 엔진, 즉 Semantic Context OS AI 커널을 분해해 살펴본다.
AI 커널 설계: VFS와 MVC(minimum viable context)
수동적인 프롬프트에서 능동적인 거버넌스로 패러다임 전환
시스템 엔지니어는 회복력 있는 엔터프라이즈급 에이전트 기반 워크플로를 구축하기 위해 근본적으로 패러다임을 전환해야 합니다. 컨텍스트를 정적인 텍스트 페이로드로 취급하는 것을 멈추고, 동적이며 경계가 설정돼 있는 구조화된 시스템 자원으로 관리해야 합니다.
전통적인 구현 패턴은 컨텍스트를 문자열 연결로 점진적으로 구성한 뒤 다음 API 호출에 맹목적으로 주입하는 수동적 프롬프트 엔지니어링에 의존합니다. 이 접근법은 다운스트림 파운데이션 LLM이 메모리 관리, 토큰 최적화, 잡음 필터링을 자신의 숨겨진 어텐션 계층 내에서 암묵적으로 처리하도록 강요하는데요. LLM은 애초에 이런 작업에 구조적으로 최적화돼 있지 않습니다.
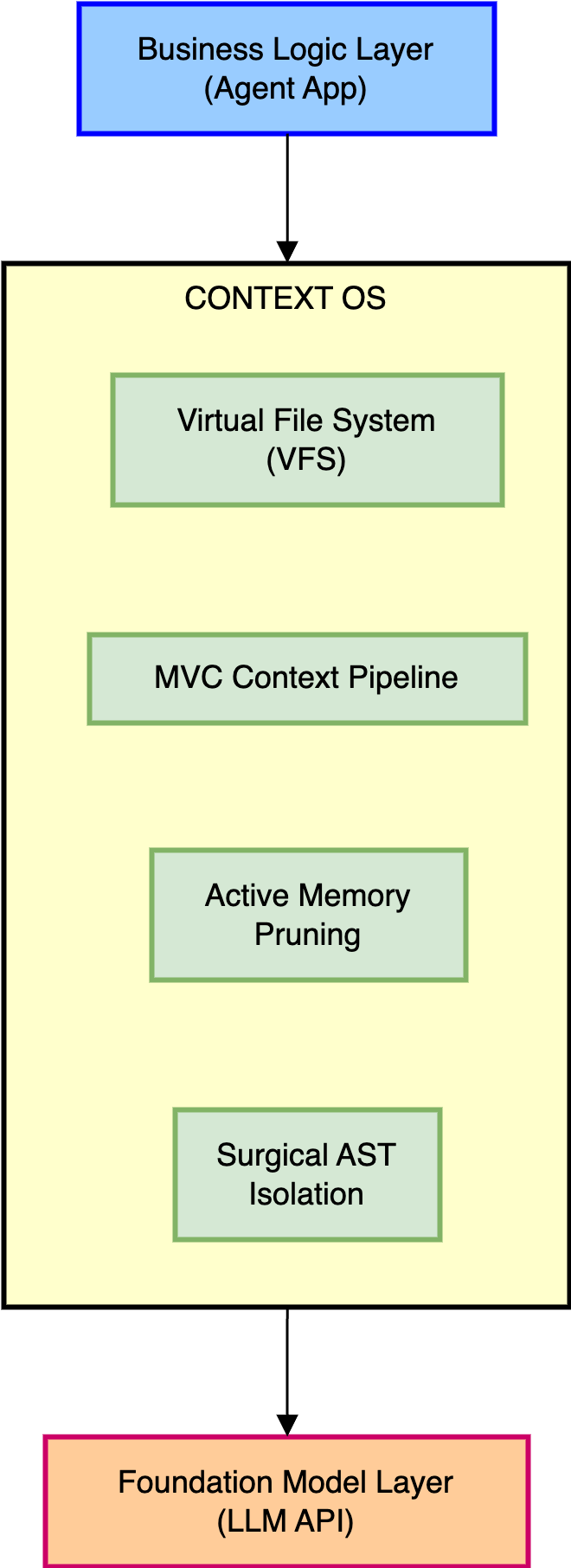
저희의 솔루션인 시맨틱 컨텍스트 OS는 애플리케이션 수준의 비즈니스 로직과 파운데이션 모델 계층 사이에 위치하는 특수화된 AI 커널을 도입합니다. 시맨틱 컨텍스트 OS는 명시적인 메모리 물류 작업을 담당합니다. 컨텍스트 창을 유한한 하드웨어 제약으로 취급하며, 토큰의 생명 주기를 능동적으로 모니터링하고, 상태 접근을 관리하며, 토큰이 전송되기 전에 엄격한 격리 정책을 적용합니다.
시맨틱 컨텍스트 OS 아키텍처의 핵심, MVC 파이프라인
시맨틱 컨텍스트 OS 아키텍처의 핵심은 MVC 파이프라인입니다. MVC 파이프라인은 거대한 텍스트 덤프를 무제한으로 먹이는 방식을 거부하고, 다음과 같은 엄격한 기술 정책을 강제합니다.
에이전트가 현재의 추론 단계를 성공적으로 수행하는 데 필요한 고도로 정제한 밀도 높은 정보의 절대 최소량만 제공한다.
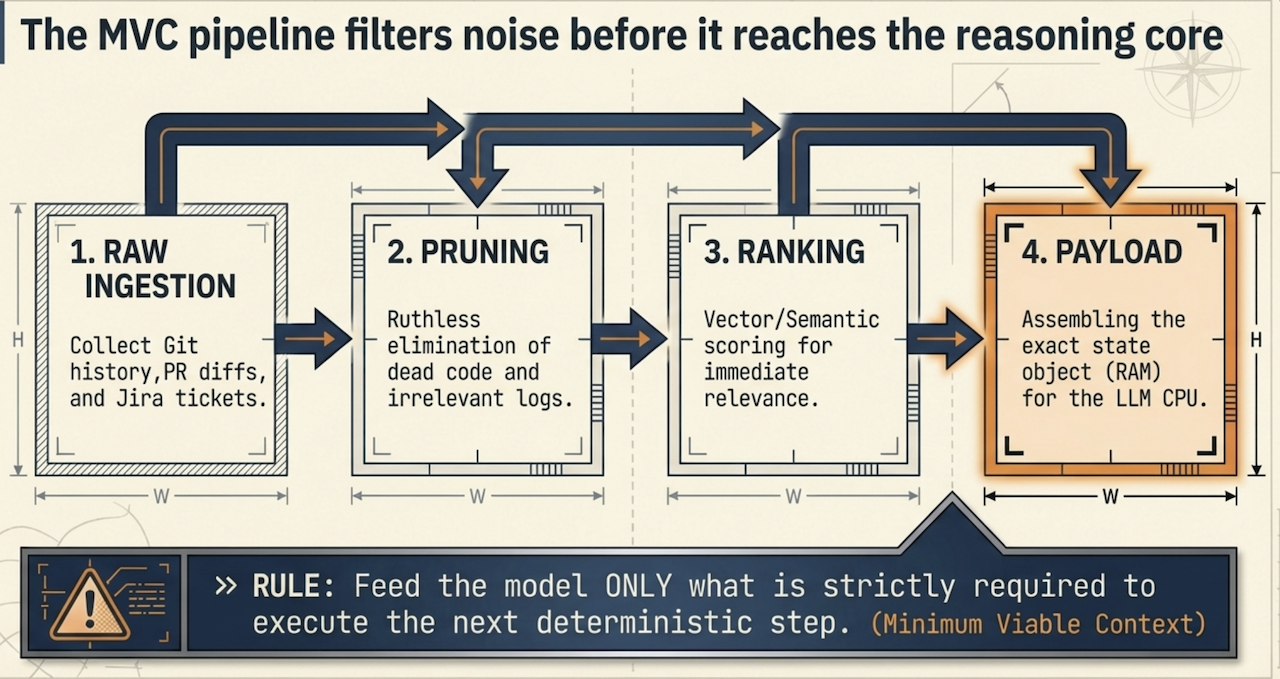
MVC 파이프라인은 모든 입력 컨텍스트 데이터를 네 가지로 구별되는 고처리량 단계로 처리합니다.
-
수집 및 토큰 매핑: 미가공 데이터 소스(소스 파일, 의존성 트리, 런타임 로그)를 수집해 정확한 모델 토크나이저(예: cl100k_base 또는 o200k_base)를 사용해서 절대 토큰 가중치에 직접 매핑합니다.
-
구조 가지치기: 시스템은 정적 코드 분석 및 구조 규칙을 사용해 컴파일러 코멘트, 참조되지 않는 보일러플레이트 import, 관련 없는 유틸리티 코드와 같은 거시적 잡음을 제거합니다.
-
시맨틱 및 의존성 순위화: 남은 정보는 시맨틱 벡터 유사도와 결정론적 AST 코드 의존성 점수를 결합한 이중 점수 메커니즘을 거쳐 완벽한 컨텍스트 정렬을 보장합니다.
-
페이로드 안정화 및 형식화: 최종적으로 최적화된 컨텍스트는 깨끗하고 예측 가능하게 구조화한 JSON 또는 XML 봉투로 정리합니다. 이와 같이 일관된 스키마를 강제함으로써 모델 경계에서 발생할 수 있는 구조적 환각을 줄입니다.
컨텍스트 창을 항상 이 고밀도 저잡음 영역에 유지함으로써 다운스트림 LLM의 어텐션 헤드는 중요한 핵심 작업 파라미터에 집중할 수 있으며, 결과적으로 어텐션 희석 함정을 우회할 수 있습니다.
에이전트 상태 관리를 위한 VFS 구현
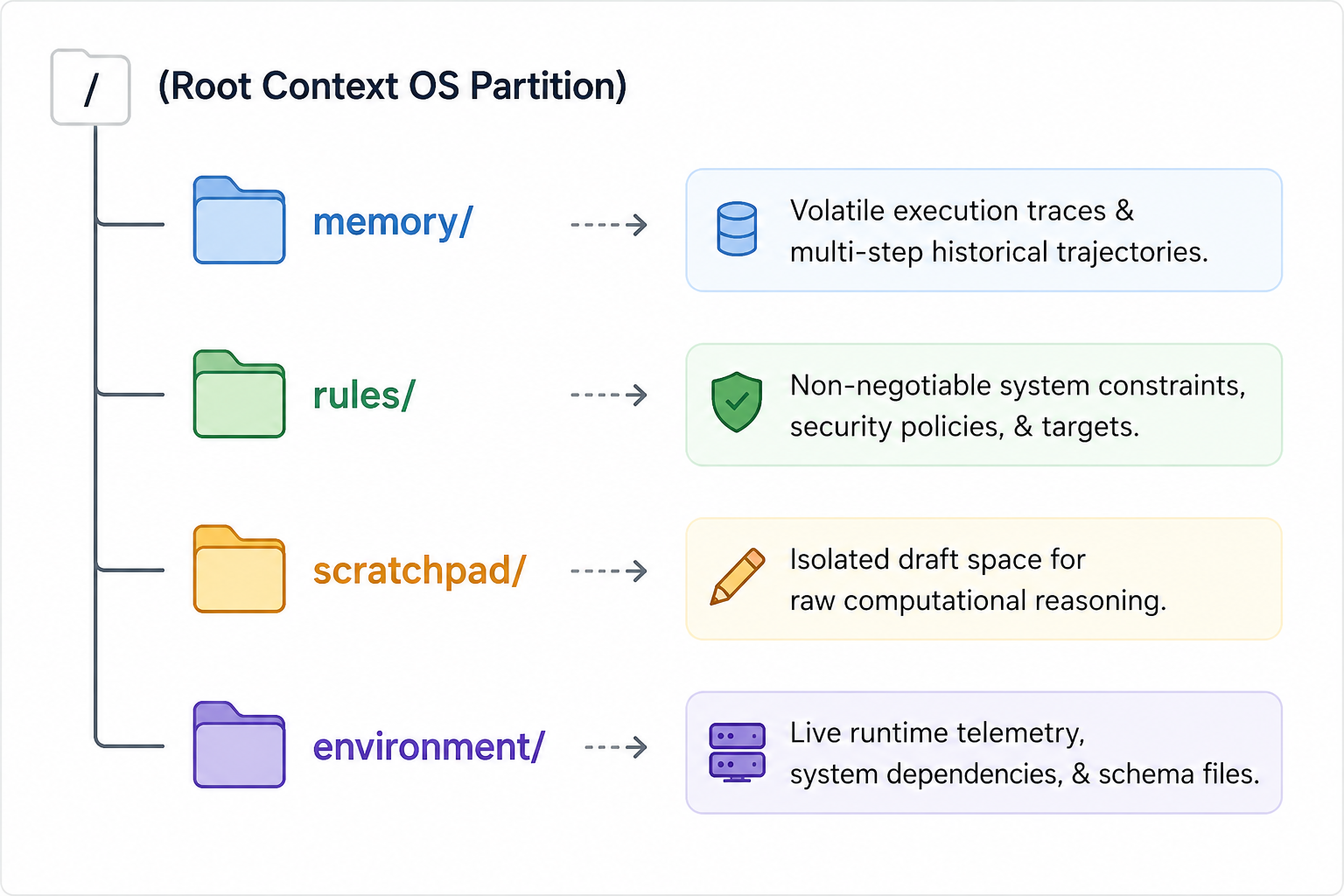
MVC 파이프라인을 효과적으로 구현하려면 AI 커널은 에이전트 내부 상태의 여러 구성 요소를 추적하고, 격리하고, 조작할 수 있는 고도로 구조화된 메커니즘이 필요합니다. 시맨틱 컨텍스트 OS는 컨텍스트 창을 POSIX 호환 운영체제의 표준 디렉터리 구조를 모방한 VFS로 추상화해서 이를 지원합니다. 평평하고 연속된 텍스트 블록 대신, 에이전트의 작업 메모리는 서로 구별되는 가상의 논리 드라이브로 분할됩니다.
-
/memory 파티션: 이 파티션은 활성 실행 루프의 단기 휘발성 이력을 관리합니다. 에이전트가 어떤 단계를 수행했고 어떤 로그를 반환했는지, 어떤 하위 작업을 완료했는지 정확히 추적합니다. 이 파티션은 매우 동적이며, 엄격한 가지치기 정책을 적용합니다.
-
/rules 파티션: 이 파티션은 절대적인 아키텍처 제약과 목표 코딩 표준, 기업 보안 정책 및 엄격한 작업 완료 정의를 보관합니다. 이 드라이브는 최대 어텐션 가중치로 보호해 하위 작업 실행 스택이 아무리 깊어지더라도 에이전트가 핵심 시스템 가드레일을 잃지 않도록 보장합니다.
-
/scratchpad 파티션: 에이전트는 다단계 계획이나 수학 계산 또는 코드 구조 초안을 수행할 때 이 격리된 샌드박스 작업 공간에서 연산을 실행합니다. 이 파티션의 데이터는 일시적이며, 논리적 결론에 도달하면 초안 단계는 폐기되고 최종적으로 최적화된 결과만 영구 핵심 메모리 드라이브로 승격됩니다.
-
/environment 파티션: 이 파티션은 런타임 컨텍스트 앵커 역할을 합니다. 외부 환경 메타데이터, 스키마 정의, 실시간 API 사양, 활성화된 서비스 간 시스템 경계를 격리하고 관리합니다. 이렇게 휘발성 환경 조건과 에이전트의 핵심 지시사항을 분리함으로써 AI 커널은 런타임 의존성이 변경될 때 /memory나 /rules의 기본 논리 상태를 오염시키거나 재설정하지 않고 서드파티 서비스 스키마를 즉시 교체하거나 새로고침하거나 갱신할 수 있습니다.
시맨틱 컨텍스트 OS는 이와 같이 VFS를 추상화해서 실행 컨텍스트의 나머지 부분을 수정하거나 오염시키지 않고 특정 메모리 세그먼트를 세분화해 외과적으로 업데이트할 수 있습니다. 예를 들어 /memory/logs의 휘발성 런타임 로그를 지우면서 /rules/security의 시스템 규칙은 그대로 유지할 수 있습니다. 이를 통해 LLM 상태 추적의 혼란스러운 특성에 결정론적 질서를 부여합니다.
아키텍처 분리: 단순한 토큰 관리를 넘어 시맨틱 컨텍스트 OS로
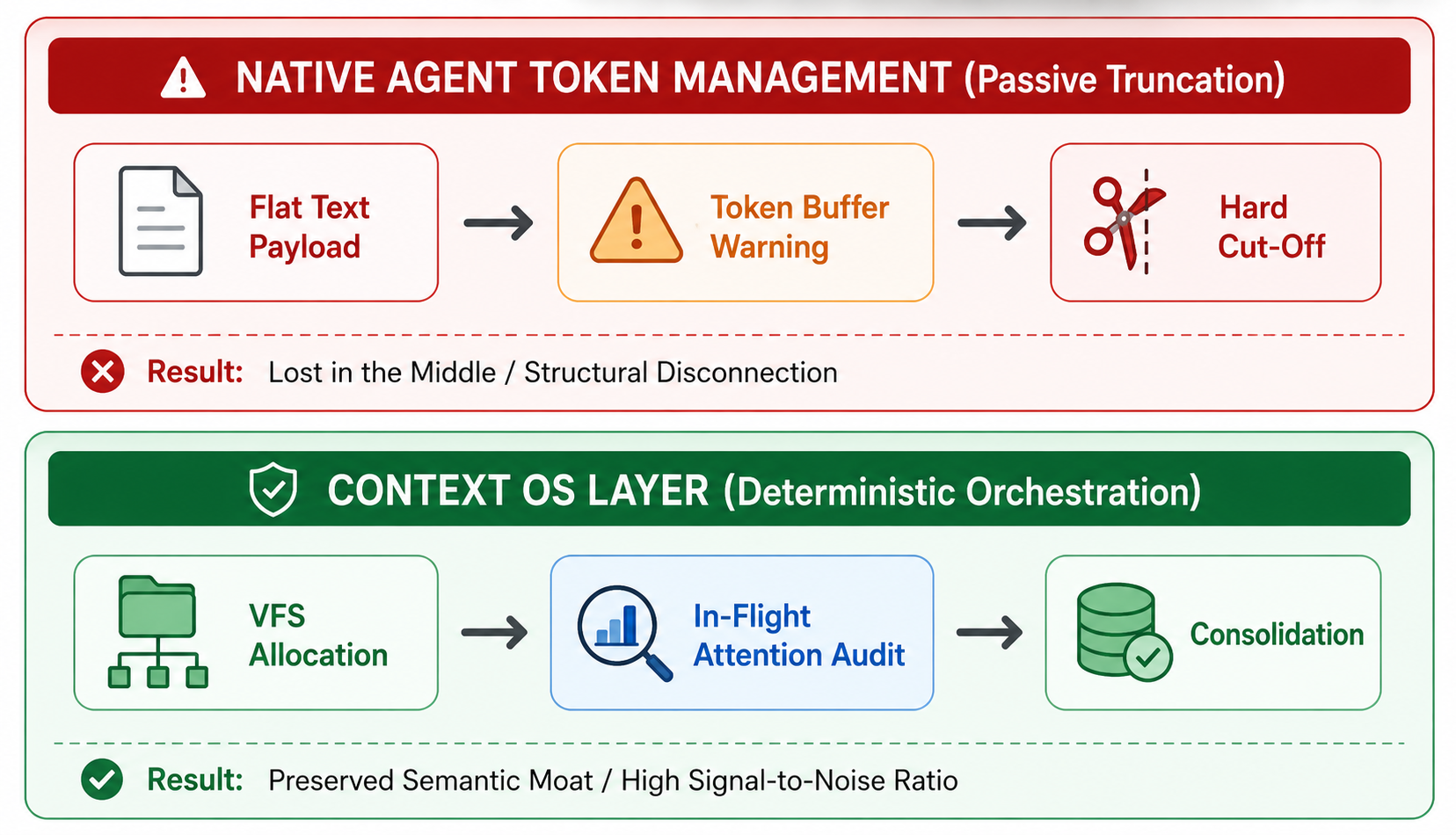
시맨틱 컨텍스트 OS 인프라를 도입할 때 근본적인 의문이 들 수 있습니다. Claude Code나 GitHub Copilot, Codex와 같은 현대의 에이전틱 생태계가 이미 토큰 관리 및 프롬프트 캐싱 기능을 내장하고 있다면 전용 시맨틱 컨텍스트 OS는 불필요한 엔지니어링 오버헤드 아닌가?
이 의문을 해결하려면 하드웨어 수준의 규정 준수와 인지적 런타임 거버넌스 사이에서 엄격하게 관심사를 분리해야 합니다.
네이티브 클라이언트 측의 토큰 관리는 근본적으로 정량적인 인프라 가드레일입니다. 이 가드레일의 역할은 문자열 할당을 모니터링하면서 다운스트림 파이프라인이 HTTP 400 Bad Request 또는 429 Rate Limit 오류를 던지지 않도록 반응적으로 절단(FIFO)하는, 시맨틱을 고려하지 않고 경계를 강제로 적용하는 것입니다. 이는 API 안정성은 최적화할 수 있지만 시맨틱 관점에서 추론 밀도를 최적화하지는 못합니다.
반면 시맨틱 컨텍스트 OS는 정성적인 시맨틱 라우터 및 로직 엔진으로 작동합니다. 단순히 전송되는 바이트의 양을 측정하는 것이 아니라 도메인을 인식하는 시맨틱 실행 경로에 따라 내부 정보 토폴로지를 능동적으로 구조화하고 감사 및 변형합니다.
| 운영 성격 | 정량적이며 시맨틱에 무관(방어적) | 정성적이며 도메인 인식(조율됨) |
| 주요 목표 | API 소진이나 실패를 방지하는 엄격한 경계 강제 적용 | 추론 드리프트와 컨텍스트 부패를 제거하기 위한 어텐션 극대화 |
| 메커니즘 | 토큰 카운팅, 슬라이딩 윈도우 축출, 정적 프롬프트 캐싱 | AST 트리 가지치기, 능동 메모리 압축, 동적 범위 오버라이드 |
| 데이터 토폴로지 | 평평한 텍스트 페이로드(모든 미가공 텍스트 데이터를 포함한 연속 문자열 봉투) | 제한된 VFS 파티션(/rules, /memory, /scratchpad, /environment) |
규칙 충돌 사례로 살펴보는 네이티브 토큰 관리의 한계
네이티브 토큰 관리에만 의존하는 방식이 왜 시스템 관점에서 실패하는지를 이해하기 위해 상속받은 코드베이스 전반에 걸쳐 깊이 있는 아키텍처 리팩토링을 수행하는 AI 에이전트 시나리오를 생각해 보겠습니다.
파이프라인이 네이티브 토큰 관리에만 전적으로 의존한다면 시스템은 모든 회사 스타일 가이드, 지역 저장소 규약, 워크스페이스 문서를 거대한 컨텍스트 창 페이로드로 모읍니다. 기본 토큰 계층은 데이터 관계를 이해하지 못하므로 모든 파일을 동일한 가중치로 취급합니다. 만약 이런 상황에서 전역 파일(/global_rules.md)은 모든 인터페이스 메서드는 snake_case를 따라야 한다고 규정하고 있는 반면, 특정 로컬 파일(/src/modules/billing/rules.md)은 구체적인 API 직렬화에 대해서는 camelCase를 강제하고 있다면 두 모순된 지시가 모델의 컨텍스트 램에 동시에 채워집니다. 멀티헤드 어텐션 메커니즘은 즉각적인 수학적 희석을 겪고, 그 결과 에이전트가 정지하거나 두 패턴 사이를 오락가락하거나 잘못된 코드 인터페이스를 환각으로 내놓는 결과를 낳습니다.
반면 시맨틱 컨텍스트 OS 아키텍처가 적용된 시스템에서는 단일 토큰이 직렬화돼 전송되기 전에 AI 커널이 상호작용 루프를 가로채고 활성 디렉터리 컨텍스트를 VFS에 등록합니다. PathAlign 엔진은 규칙 파일의 구조적 계층을 파싱합니다. AI 커널은 ‘billing’ 범위의 규칙 블록이 전역 설정 파일보다 더 깊고 높은 우선순위의 네임스페이스 경로에 위치해 있다는 것을 인식하고 동적 규칙 충돌 오버라이드를 실행합니다. 상충하는 전역 지시는 운영 범위에서 외과적으로 제거되고, 단일화된 고밀도 지시 페이로드만 읽기 전용 /rules 드라이브로 승격됩니다. 그 결과 네트워크로 전송되는 토큰 봉투에는 올바르게 실행하기 위해 정제된 핵심 내용만 담겨 있습니다.
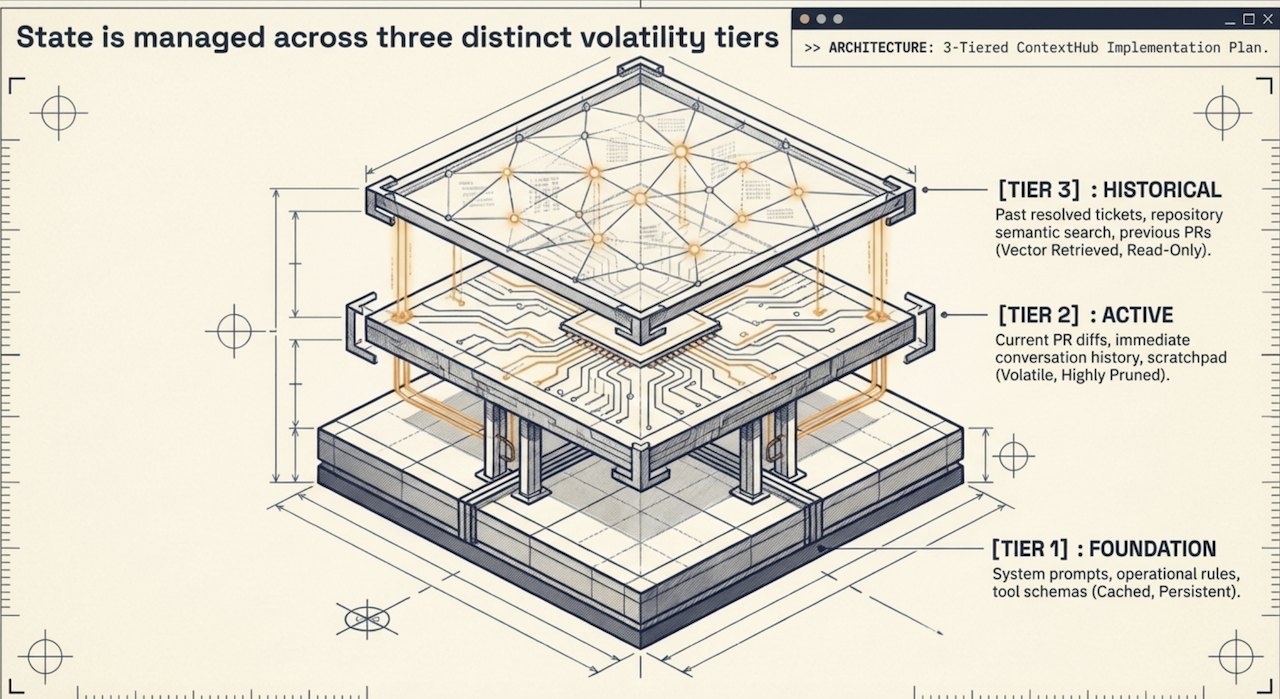
설계를 실행으로 연결하기
VFS 내 데이터 파티션을 지역화하고 엔터프라이즈급 보안 경계를 설정하면 안전한 런타임 기반을 구축하기 위한 구조적 청사진을 얻을 수 있습니다. 하지만 이와 같이 경계가 설정된 컨텍스트를 다중 턴 자율 루프 전반에 걸쳐 유지하려면 능동적인 실시간 계산을 수행해야 합니다. 다음 섹션에서는 시맨틱 컨텍스트 OS 아키텍처를 기반으로 프로덕션 환경에서 최소 유효 컨텍스트 제약을 능동적으로 강제하도록 설계한 저수준(low-level) 수학 및 프로그램 루틴인 ‘톱니 메모리 모델’과 ‘PathAlign 단계’을 살펴보겠습니다.
핵심 아키텍처 메커니즘: 톱니 메모리 모델과 PathAlign 단계
톱니 메모리 모델: 런타임에서 능동적으로 가지치는 알고리즘
시맨틱 컨텍스트 OS는 다중 턴 자율 작업 전반에서 갑작스러운 OOM 에러 또는 컨텍스트 절단 없이 MVC 파이프라인의 제약을 강제하기 위해 톱니 메모리 모델 알고리즘을 구현합니다. 이 알고리즘은 토큰 소비를 동적으로 확장하고 최적화하는 능동적인 런타임 관리 알고리즘입니다.
수동적인 데이터 전달 프레임워크와 달리 톱니 메모리 모델 알고리즘은 VFS 파티션 내의 활성 토큰 수를 지속적으로 추적합니다. 토큰 수는 에이전트가 외부 환경과 상호작용함에 따라 선형적으로 증가하며 미리 정의한 포화 임곗값으로 다가갑니다. 그러다가 임곗값을 초과하는 순간 AI 커널은 실행을 멈추고 다음 두 가지 주요 작업을 수행하는 백그라운드 압축 프로세스를 생성합니다.
-
외과적 토큰 가지치기: /memory 내부 토큰의 교차 어텐션 가중치 이력을 평가해서 특정 표준편차 이하로 가중치가 떨어진 토큰은 즉시 시스템에서 제거합니다.
-
시맨틱 통합: 활성 텍스트 체인 또는 다중 턴 대화 로그가 고효율 유틸리티 모델로 전달돼 미가공 대화 스레드를 고밀도의 시맨틱 상태 벡터로 압축합니다.
압축 프로세스를 거치고 나면 활성 토큰 수가 다시 안전한 수준으로 떨어집니다. 그 결과 텔레메트리 그래프에 아래와 같이 톱니 패턴을 생성합니다. 이 사이클은 무한히 반복되며 에이전트를 최적의 추론 영역 내에 위치시킵니다.
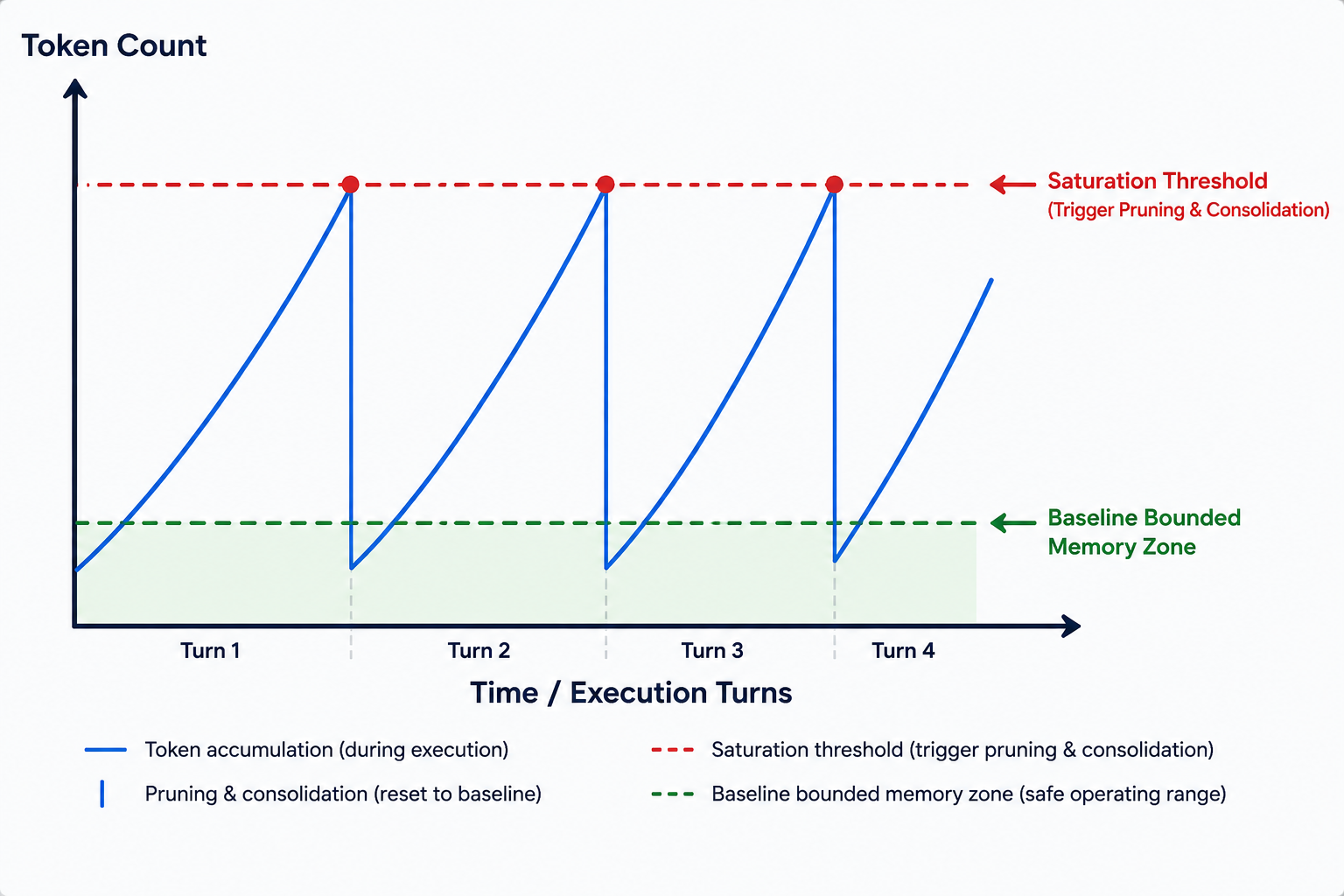
아래는 톱니 메모리 모델 알고리즘이 작동하는 방식을 개념적으로 나타낸 것입니다.
# Pseudo-Code: Semantic Context OS In-Flight Memory Compaction Kernel Daemon # Operating as an Asynchronous, Non-blocking Intercepting Middleware class ContextOSKernel: def __init__(self, vfs_driver, token_encoder, saturation_threshold=0.70): self.vfs = vfs_driver self.encoder = token_encoder self.threshold = saturation_threshold self.is_compacting = False def on_agent_request_intercepted(self, request_payload): """ Triggered immediately when Claude Code / Codex dispatches an API payload. Ensures the context window remains inside the optimal semantic zone before transmission. """ # Step 1: Compute real-time input token allocation across VFS partitions active_tokens = self.encoder.count_allocated_tokens(self.vfs.read_partition('/memory')) max_capacity = system_hardware_constraints.get_max_context_window() current_usage_ratio = active_tokens / max_capacity # Step 2: Evaluate the Saturation Threshold (Sawtooth Trigger Point) if current_usage_ratio >= self.threshold and not self.is_compacting: # Spawn asynchronous worker to prevent blocking the active client streaming IO loop asynchronous_worker_pool.dispatch(self.execute_sawtooth_compaction) # Step 3: Inject surgically isolated codebase graph from PathAlign Engine purified_code_subgraph = PathAlignEngine.extract_syntax_subgraph(request_payload.target_files) self.vfs.write_partition('/environment/codebase', purified_code_subgraph) # Step 4: Re-serialize localized VFS states into a unified, high-density token envelope return self.vfs.consolidate_to_raw_json_payload() def execute_sawtooth_compaction(self): """ Asynchronous Kernel Routine executing in-flight pruning and semantic consolidation. """ self.is_compacting = True try: # Enforce an immutable isolation lock on system guardrails to prevent memory corruption self.vfs.acquire_write_lock('/rules') # Fetch diagnostic matrix telemetry (e.g., from Langfuse or local runtime trace) attention_metrics = telemetry_engine.get_active_attention_logs() # Identify target nodes containing obsolete execution outputs, stale errors, or duplicated traces stale_nodes = self.filter_low_weight_tokens( target_partition=self.vfs.read_partition('/memory/history'), weights=attention_metrics ) # Execute Surgical Pruning for node in stale_nodes: self.vfs.delete_node(node) # Execute Lossless Semantic Consolidation on long conversational turns raw_history_chain = self.vfs.read_partition('/memory/history') # Compress raw logs into structured state vectors while strictly protecting critical entities consolidated_state_vector = state_summarizer_utility.compress( payload=raw_history_chain, policy="Preserve entity names, function signatures, error codes, and compliance constraints" ) # Commit consolidated vector and release the pipeline self.vfs.write_partition('/memory/consolidated_state', consolidated_state_vector) self.vfs.clear_partition('/memory/history') finally: self.vfs.release_write_lock('/rules') self.is_compacting = False logger.info("Sawtooth memory compaction cycle executed successfully. Optimal context restored.")톱니 메모리 모델은 또한 자율적이고 알고리즘 성향을 띈 커널 루틴이라고 할 수 있습니다. 실패가 발생할 때까지 기다리지 않고 능동적으로 어텐션 감쇠를 모니터링하며 실행 중 메모리 패턴을 재구성해 절대적인 시스템 안정성을 유지합니다.
외과적 컨텍스트 검색: PathAlign 단계
AI 에이전트를 코드 리뷰, 취약점 발견 또는 자동 리팩토링과 같은 소프트웨어 인텔리전스 작업에 적용할 때 전통적인 시맨틱 벡터 검색(표준 RAG)은 완전히 실패합니다. 코드는 자연어가 아닙니다. 고정 문자 수 제한에 따라 평평한 텍스트 블록으로 코드베이스를 청킹하면 시맨틱 구문 트리가 완전히 파괴되고 중요한 임포트 그래프와 부모-자식 의존성이 끊어집니다.
건초 더미 같은 대규모 저장소에서 바늘을 찾는 문제를 해결하기 위해 시맨틱 컨텍스트 OS에는 PathAlign 단계를 도입했습니다. PathAlign은 벡터 거리 조회를 AST 기반 격리로 대체합니다.
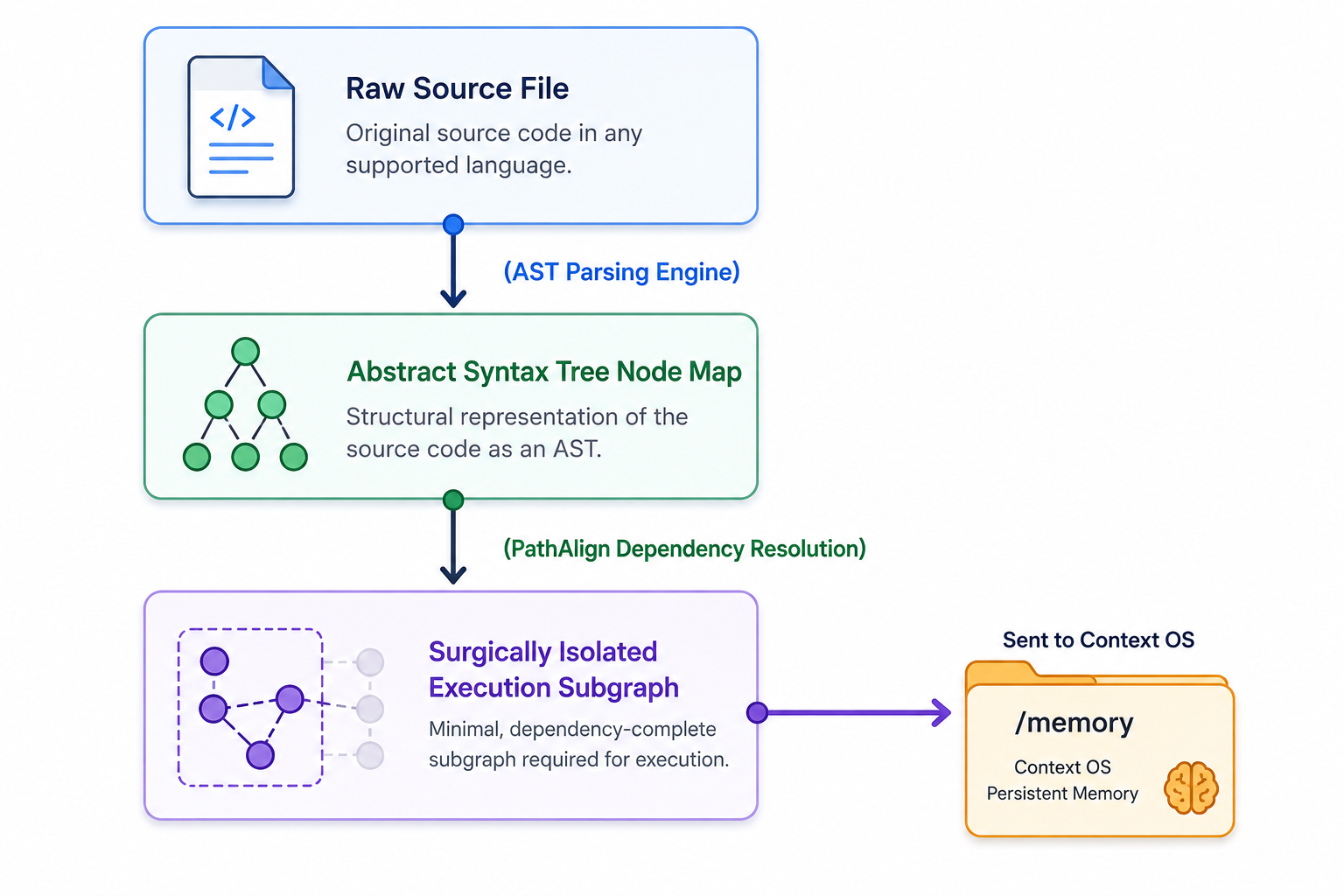
에이전트가 특정 비즈니스 함수나 대규모 시스템 전반의 오류 추적을 검토해야 할 때 PathAlign은 다음과 같은 세부 실행 절차를 실행합니다.
-
정적 AST 파싱: 대상 소스 파일을 계층적 구문 트리로 메모리에 컴파일해 모든 클래스 정의, 인터페이스 구현, 함수 호출 및 변수 참조를 식별합니다.
-
제어 흐름 및 의존성 해석: 대상 함수 노드에서 바깥으로 향하는 명시적 실행 경로를 추적해 정확한 의존성과 다운스트림 호출 관계를 매핑합니다.
-
컨텍스트 그래프 격리: 코드 경로를 이해하는 데 필요한 명시적 실행 서브 그래프만 격리하고, 관련 없는 주석이나 보조 함수, 연결되지 않는 코드는 완전히 제거합니다.
이와 같은 방법으로 외과적으로 격리한 실행 그래프는 고밀도의 구조화된 페이로드로 구성돼 VFS에 직접 배치됩니다. 이를 통해 에이전트는 대규모 저장소 내에서 어텐션 희석 없이 복잡한 오류를 찾아낼 수 있습니다.
실행을 평가로 연결하기
톱니 메모리 모델 데몬과 PathAlign 파서 메커니즘은 시맨틱 컨텍스트 OS 내에서 토큰 거버넌스에 결정론적 질서를 부여합니다. 이제 이 시스템의 타당성을 실증적 프레임워크를 통해 확인해야 합니다. 다음 섹션에서는 주관적이고 감각에 의존하는 검증을 넘어 컨텍스트 수명 주기를 수학적으로 검증하기 위해 설계한 엔지니어링 텔레메트리 및 목표 성능을 살펴보겠습니다.
성능 평가 프레임워크 설계 목표
제안된 관찰가능성 방법론 및 검증 전략
최근 엔터프라이즈 플랫폼에서 AI 에이전트를 평가하는 방식이 대부분 주관적 시각 분석(일명 ‘vibe-based engineering’)에 의존하면서 엔지니어링 관점에서 엄격성이 심각히 결여되고 있습니다. 이번 섹션에서는 절대적인 기술 규율을 수립하기 위해 컨텍스트 생애 주기를 수학적으로 감사하도록 설계된 아키텍처 평가 프레임워크를 소개하겠습니다.
-
Langfuse 추적을 통한 의도된 텔레메트리: 대상 아키텍처는 모든 VFS 파티션 교체 경계 지점에 실시간 추적 ID를 부여합니다. 이 프레임워크는 런타임 메모리 압축 루프 동안 각 어텐션 헤드가 어떻게 반응하는지 정확히 기록하는 어텐션 분포 맵을 캡처하도록 설계했습니다.
-
골든 데이터셋 청사진: 추론 일관성을 스트레스 테스트하기 위해 30개의 복잡한 엔지니어링 풀 리퀘스트로 구성한 특수 저장소 베이스라인을 설계했습니다. 이 모음은 여러 파일의 교차 의존성 및 복잡한 코드 분기를 포함해 객관적 평가 기준을 제공합니다。
추정 성능 궤적 및 실증적 목표
프로토타입 단계에서 수행한 초기 소규모 테스트에서는 레거시 베이스라인 모델(1.1.0 버전 표준 문자열 집계)과 2.0.0 버전 컨텍스트 OS 능동 메모리 아키텍처를 비교했고, 긍정적인 성능 궤적을 보여줬습니다.
방법론 관련 면책 고지 사항: 아래 제시한 지표는 핵심 아키텍처 설계 목표와 예상되는 최적화 추세를 나타냅니다. 평가 하네스는 엔터프라이즈 프로덕션 워크로드에 배포하기 전에 통계적 재현성을 확실히 보장하기 위해 지속적으로 방법론을 보정하고 있습니다.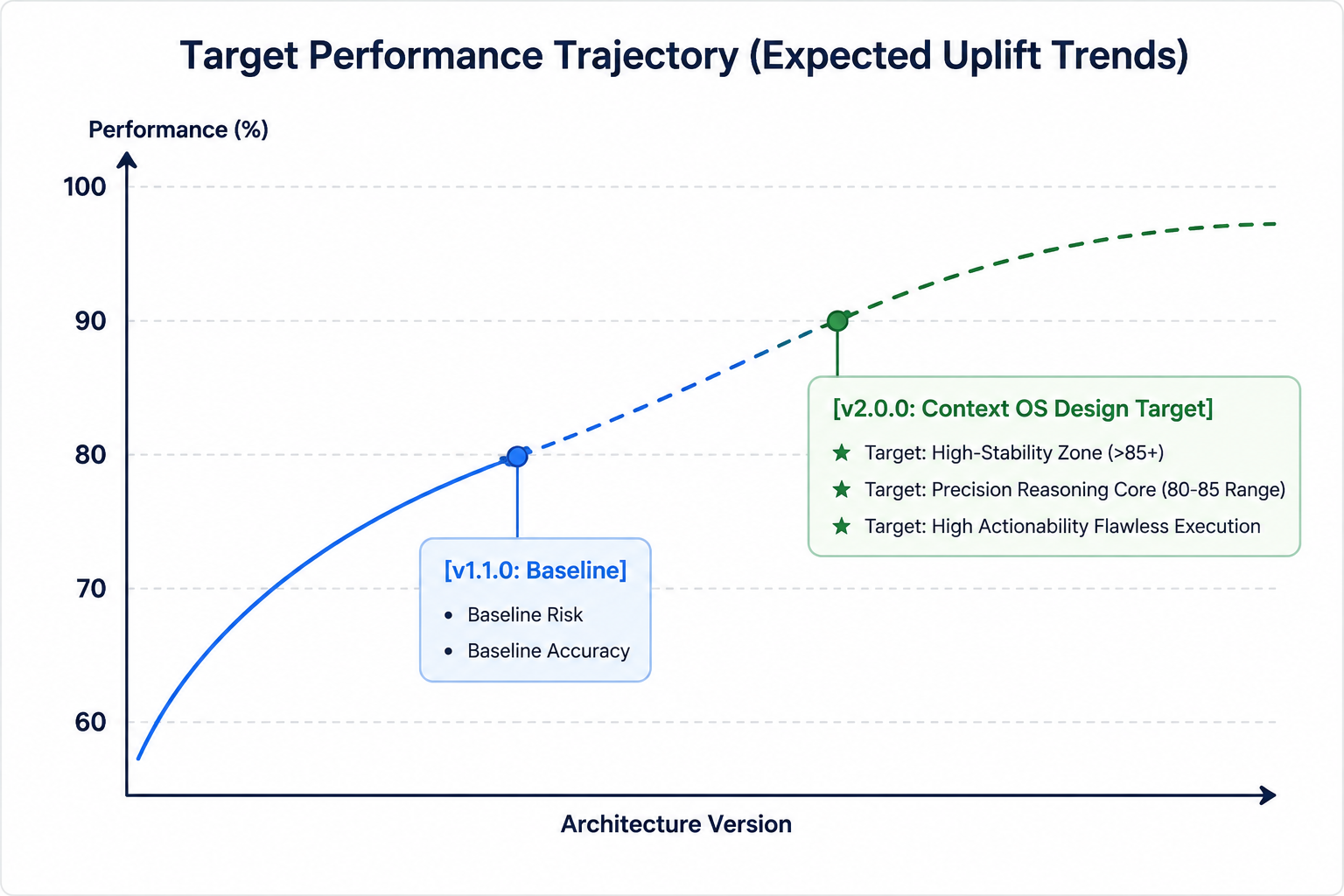
궤적 1: 자원 최적화 및 토큰 소비 한계
초기 실행 루프 동안 톱니 메모리 모델 내 압축 메커니즘이 총 토큰 할당량을 낮추는 뚜렷한 하향 궤적을 보였습니다. 궤적 1에서는 베이스라인과 비교해 토큰 오버헤드를 20~25% 감소시키는 것이 목표입니다. /memory에서 가중치가 낮은 과거 노드를 체계적으로 제거해서 시스템이 실행 중 유지해야 하는 토큰 및 컨텍스트 부담을 최소화하는 것이 목표입니다.
궤적 2: 정밀도 향상 및 신호-잡음 분배
1.1.0 버전 기준으로 에이전트의 기술적 정확도 점수는 ‘중간 정보 유실’ 구간의 어텐션 감쇠 때문에 제한됐습니다. 반면 2.0.0 버전에서는 초기 추적 결과를 기준으로 목표 정밀도가 80점 이상인 최적 구간으로 성능이 향상될 것으로 예상합니다. 이 궤적은 PathAlign 단계에서 추진됩니다. PathAlign 단계에서 컴파일된 구문 그래프만 모델 경계에 도달하도록 만들어서 신호 대 잡음비를 약 15~20% 개선할 것으로 추정합니다.
궤적 3: 거버넌스 연속성 및 위험 평가 경계
가장 중요한 궤적 변화는 위험 및 영향 평가 지표에서 나타납니다. 해당 지표는 높은 회복 탄력성을 갖춘 목표 구간인 85-90점 이상 수준으로 향상될 것으로 예상합니다. 이러한 개선은 기본 정책을 읽기 전용 /rules VFS 파티션 내에 고정함으로써 가능해집니다. 이를 통해 시스템 아키텍처는 에이전트가 장시간에 걸친 다중 턴 추론 워크플로 동안 기업 컴플라이언스 가이드라인을 잊거나 그 가이드라인에서 벗어나는 현상을 구조적으로 방지합니다.
결론: 모델은 범용재, 컨텍스트 아키텍처가 지식 재산
AI 생태계가 빠른 속도로 진화하면서 최첨단 파운데이션 모델의 기본 능력은 빠르게 수렴하고 있습니다. 순수 추론 능력, 네이티브 컨텍스트 창 크기, 가격 구조는 주요 클라우드 제공 업체 전반에 걸쳐 점차 범용화되고 있습니다. 이런 환경에서 단순히 API를 호출하거나 프롬프트에 문자열을 추가하는 것은 더 이상 지속 가능한 엔지니어링 우위가 아니라 기본 배관 작업에 불과합니다.
2026년 엔터프라이즈 AI 시스템의 결정적 경쟁 우위는 파운데이션 모델의 가중치에 있지 않습니다. 경쟁 우위는 전적으로 이러한 모델의 입력 환경을 관리하는 오케스트레이션 계층에 존재합니다. 그런 의미에서 시맨틱 컨텍스트 OS는 진정한 자율성과 신뢰성을 향한 성숙하고 체계적인 진전입니다. 저희는 능동 AI 커널을 도입하고, 엄격한 최소 실행 가능 컨텍스트 파이프라인을 강제하며, 구조화된 VFS를 통해 메모리를 추상화하고, 톱니 메모리 모델과 같은 고급 런타임 압축 알고리즘을 적용해서 LLM 어텐션의 혼란스럽고 비결정적인 특성을 잘 규율된 엔터프라이즈급 런타임 자산으로 전환합니다.
궁극적으로 컨텍스트 계층을 통제하고 활용하는 능력은 단순히 텍스트를 생성하는 수준을 넘어 대규모 환경에서 복잡한 소프트웨어 엔지니어링 작업을 안정적으로 수행하는 AI 에이전트를 구축하기 위한 마지막 엔지니어링 장벽이 될 것입니다.
기술 출처 및 참고문헌
엄격한 엔지니어링 무결성과 전문적 투명성을 유지하기 위해 업계에서 널리 확립된 방법론과 Context OS 프레임워크 내에서 저희 팀이 독자적으로 고안한 기술적 혁신의 경계를 명확히 구분하겠습니다.
업계 표준 기반 기술
이 글에서 소개하는 연구의 이론적 기반은 글로벌 AI 커뮤니티가 구축해 온 다음과 같은 핵심 패러다임에 기반합니다.
- CPU-RAM 비유(Karpathy Metaphor): LLM의 추론 루프와 현대 컴퓨팅 아키텍처 간의 개념적 대응 관계를 설명하기 위해 Andrej Karpathy가 제시한 비유
- ‘중간 정보 유실’ 현상: Stanford 대학의 Liu 등이 발표한 Lost in the Middle: How Language Models Use Long Context, Liu et al., 2023 논문에서 체계적으로 분석한 긴 컨텍스트 환경의 구조적 문제
- 크기 조정 내적 어텐션: Google의 기념비적 논문 Attention Is All You Need (Vaswani 등, 2017)에서 제안된 멀티헤드 어텐션의 수학적 기반으로, Query(Q), Key(K), Value(V) 행렬을 이용한 어텐션 계산 방식을 의미
저자들이 독자적으로 고안한 핵심 기술
다음 구성 요소들은 엔터프라이즈 규모 확장에서 발생하는 병목 문제를 해결하기 위해 저자들이 처음부터 설계·구현한 독자적 시스템 아키텍처와 알고리즘입니다.
- 시맨틱 컨텍스트 OS 프레임워크: 결정론적 메모리 할당을 관리하기 위해, 독립적인 AI 커널을 로컬 인터셉팅 루프백 프록시(localhost:8080) 형태로 내장한 아키텍처 패러다임
- VFS 상태 엔진: 평탄한 토큰 공간을 구별된 POSIX 스타일의 디렉터리 파티션(/rules, /memory, /scratchpad, /environment)으로 분리해 행위를 엄격히 격리하고 가드레일을 적용하는 추상화 계층
- 톱니 메모리 모델: 실행 중 동적 런타임 압축 알고리즘 및 비동기 이벤트 기반 토큰 최적화 데몬
- PathAlign 단계: 네트워크 환경에서 AST 트리 가지치기를 활용해 컴파일러 실행 서브그래프를 분리 및 추출하는 정적 분석 방법론
Tech-Verse 2026 개최 안내 — 6월 29일

이 글은 이벤트의 공식 기사로 공개되었습니다.
Tech-Verse 2026은 LY Corporation가 개최하는 기술 컨퍼런스입니다.
혁신적인 기술적 도전 과정과 현장의 생생한 인사이트를 공유합니다.
YouTube LIVE를 통한 생중계도 꼭 시청해 주세요.
https://tech-verse.lycorp.co.jp/2026/ko/









![[G-브리핑] 컴투스, 임직원 참여형 ESG 플로깅 활동](https://pimg.mk.co.kr/news/cms/202606/11/news-p.v1.20260611.0f1bb9233318459cb7ad7f04a40a2d5c_R.jpg)



 English (US) ·
English (US) · 