시작하며
안녕하세요. 사내 클라우드 서비스 Verda와 사내 모니터링 도구 IMON에 Infrastructure as Code(이하 IaC)를 적용한 LINE Plus SRE 팀의 이채승, 조은학입니다. IaC는 서버나 로드 밸런서, DNS, 모니터링 설정처럼 운영에 필요한 인프라 리소스를 웹 UI에서 직접 수정하는 대신 코드로 선언하고 관리하는 방식입니다.
저희는 Verda의 VM(virtual machine), LB(load balancer), DNS(domain name service), 쿠버네티스 리소스와 IMON의 알림 그룹(alert group), 알림 규칙(alert rule), 알림 모니터(alert monitor)를 OpenTofu/Terragrunt로 관리하고 있습니다. 현재 약 1,500개의 리소스가 코드로 선언되어 있으며, 7개 서비스의 인프라 변경은 모두 PR(pull request) 리뷰와 CI/CD(continuous integration/continuous deployment) 파이프라인을 거쳐 반영됩니다. 코드와 실제 인프라의 차이도 매일 자동으로 감지해서 알림으로 전달해 줍니다.
처음부터 이런 구조였던 것은 아닙니다. 이미 운영 중인 약 300대의 VM, 약 160개의 LB, 약 350개의 DNS 레코드를 코드로 옮겨야 했고, Verda 대시보드나 스크립트를 사용하거나 위키에 절차를 정리해 놓는 등 팀마다 다른 방식으로 관리하던 설정을 GitOps(Git 기반 운영 자동화)라는 하나의 흐름으로 모아야 했습니다.
이 글에서는 이 과정을 공유하려고 합니다. 왜 IaC가 필요했는지, 기존 리소스를 어떻게 가져왔는지, 운영 중 어떤 문제를 만났는지, 그리고 어떻게 Slack과 AI 에이전트를 이용해 코드 생성까지 자동화하려고 하는지 공유하겠습니다.
왜 IaC를 도입했는가
운영 규모가 커지면서 생긴 과제
기존에는 여러 팀이 각자의 방식으로 인프라를 관리하고 있었습니다. 어떤 팀은 Verda 대시보드에서, 어떤 팀은 스크립트로, 어떤 팀은 문서로 정리해 놓은 매뉴얼 절차대로, 설정 기록 방식도 위키, 개인 문서, GitHub 등 제각각이었습니다.
각 방식에 문제가 있는 것은 아니었지만, 서비스와 리소스가 늘어나면서 아래와 같이 몇 가지 공통된 어려움이 생기기 시작했습니다.
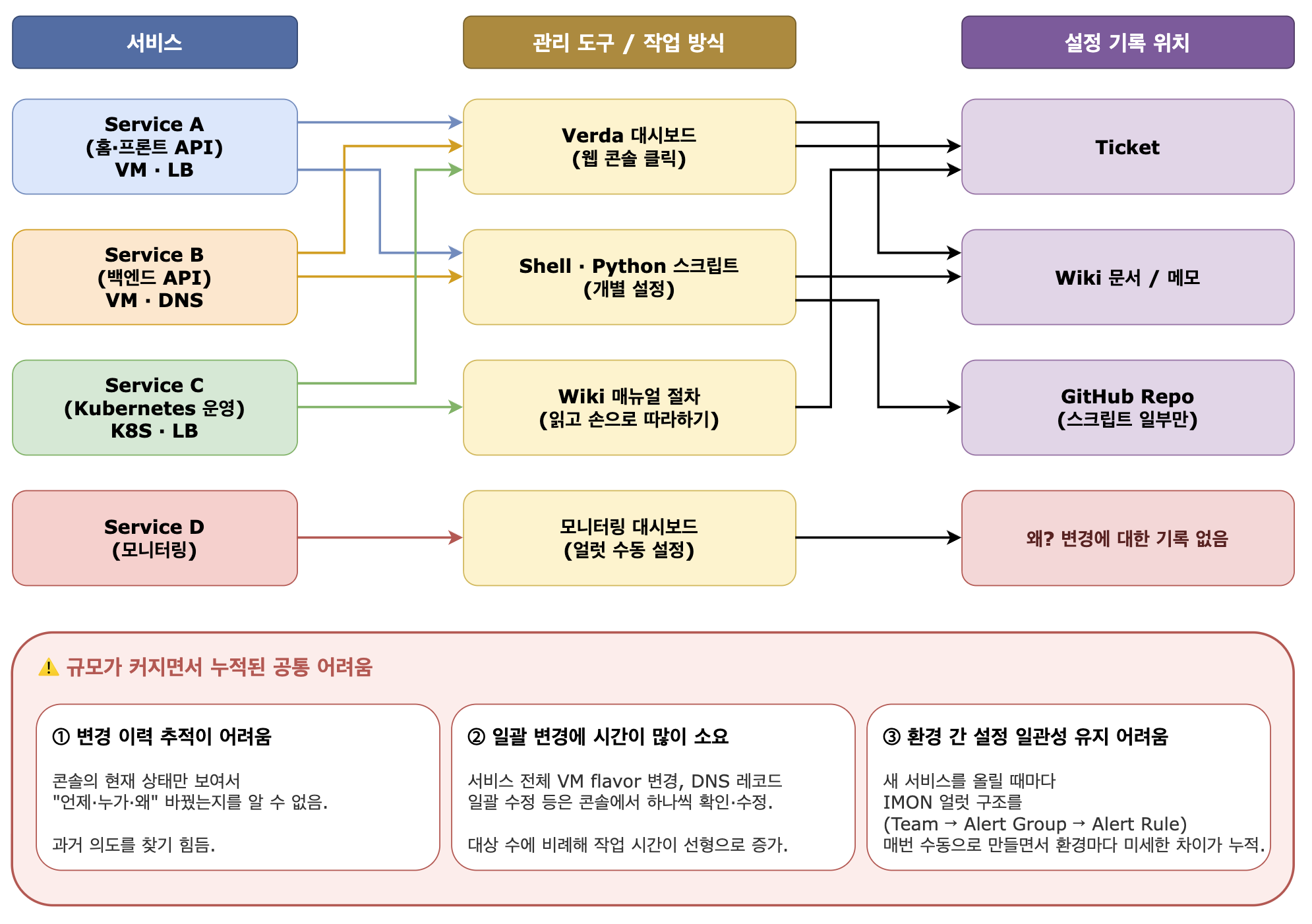
이런 어려움은 대상이 몇 개 안 될 때는 단순한 운영 작업으로 취급할 수 있지만, 규모가 커질수록 부담이 누적돼 감당하기 어려워집니다. 그래서 저희는 인프라를 코드로 관리할 필요가 있다고 판단했습니다. 리소스의 상태를 명시적으로 정의하고, 변경 사항을 리뷰하며, 같은 작업을 자동으로 반복할 수 있게 만드는 방식이 필요했습니다.
콘솔에서 코드로, GitOps라는 답
앞서 정리한 과제들을 놓고 콘솔 기반 운영과 IaC 기반 운영을 항목별로 비교해 봤습니다. 각 항목에서 저희가 기대한 변화는 다음과 같습니다.

여섯 가지 항목이 가리키는 방향은 하나입니다. 원하는 인프라 상태를 Git에 선언하고, 모든 변경 이력을 Git에 남겨 투명하게 관리하는 것입니다. 소프트웨어를 배포할 때에는 아무도 SSH로 서버에 파일을 직접 올리지 않습니다. Git에 코드를 푸시하면 CI/CD가 빌드하고 리뷰한 뒤 배포합니다. 그런데 인프라는 아직도 많은 팀에서 콘솔에서 클릭해 서버를 만들고 위키에 설정을 기록합니다.
GitOps는 이 간극을 메웁니다. 원하는 인프라 상태(desired state)를 Git 저장소에 선언하고, 변경은 반드시 PR로 진행하며, 모든 변경 이력이 Git에 남습니다.
“Your infra should be as reviewable, versionable, and reproducible as your application code.”
“인프라도 애플리케이션 코드처럼 리뷰 가능하고, 버전 관리 가능하며, 재현 가능해야 한다.”
단순히 자동화를 위한 것이 아닙니다. 인프라도 애플리케이션 코드와 동일한 수준의 엔지니어링 산출물로 관리하고 싶었습니다. 리뷰 없이는 변경도 없고, 흔적 없는 변경도 존재하지 않는 환경으로 이사할 준비를 했습니다.
이사 준비
도구 선택
이사를 시작하기 전에 먼저 어떤 도구를 사용할지부터 정리했습니다. 이번에 검토한 핵심 도구는 OpenTofu와 Terragrunt입니다.
OpenTofu는 Terraform의 오픈소스 포크로, 기존 Terraform과 동일한 HCL(HashiCorp Configuration Language) 문법과 프로바이더(provider) 호환성을 유지하면서도 오픈소스 라이선스 기반으로 사용할 수 있는 IaC 도구입니다. 기존 Terraform 기반의 작성 방식과 크게 다르지 않기 때문에 학습 비용이 낮고, 이미 사용 중이던 프로바이더나 모듈 구조도 대부분 그대로 가져갈 수 있다는 점이 장점이었습니다.
OpenTofu와 모듈화
OpenTofu를 도입하면서 가장 먼저 정리한 것은 반복해서 사용하는 인프라 구성을 모듈로 분리하는 일이었습니다. VM, 로드밸런서, 모니터링 알림 등을 모듈로 만들어 두면 여러 팀에서 같은 모듈에 값만 넘겨 각자의 인프라를 만들 수 있습니다. 모듈은 버전으로 관리하며 변경돼 버전이 올라가도 모든 환경에 즉시 영향을 주는 것이 아니라, 필요한 곳에서만 명시적으로 버전을 올려 적용할 수 있는 형태로 구성했습니다.
그런데 모듈화만으로는 부족했습니다. 모듈로 만들면서 리소스 정의가 중복되는 현상은 줄었지만, 환경별로 모듈 호출이나 백엔드 및 프로바이더 설정이 반복되는 현상까지 제거하기는 어려웠습니다. 이 때문에 리소스가 늘어날수록 비슷한 코드가 여러 디렉토리에 계속 생겼습니다.
DRY를 위한 Terragrunt
Terragrunt는 OpenTofu를 사용할 때 환경 구성까지 DRY(don’t repeat yourself, 같은 코드를 반복하지 않는 원칙)를 확장할 수 있는 래퍼(wrapper)입니다. 공통 설정은 상위 root.hcl에 한 번만 정의하고, 각 환경에는 달라지는 입력(inputs)만 남깁니다.
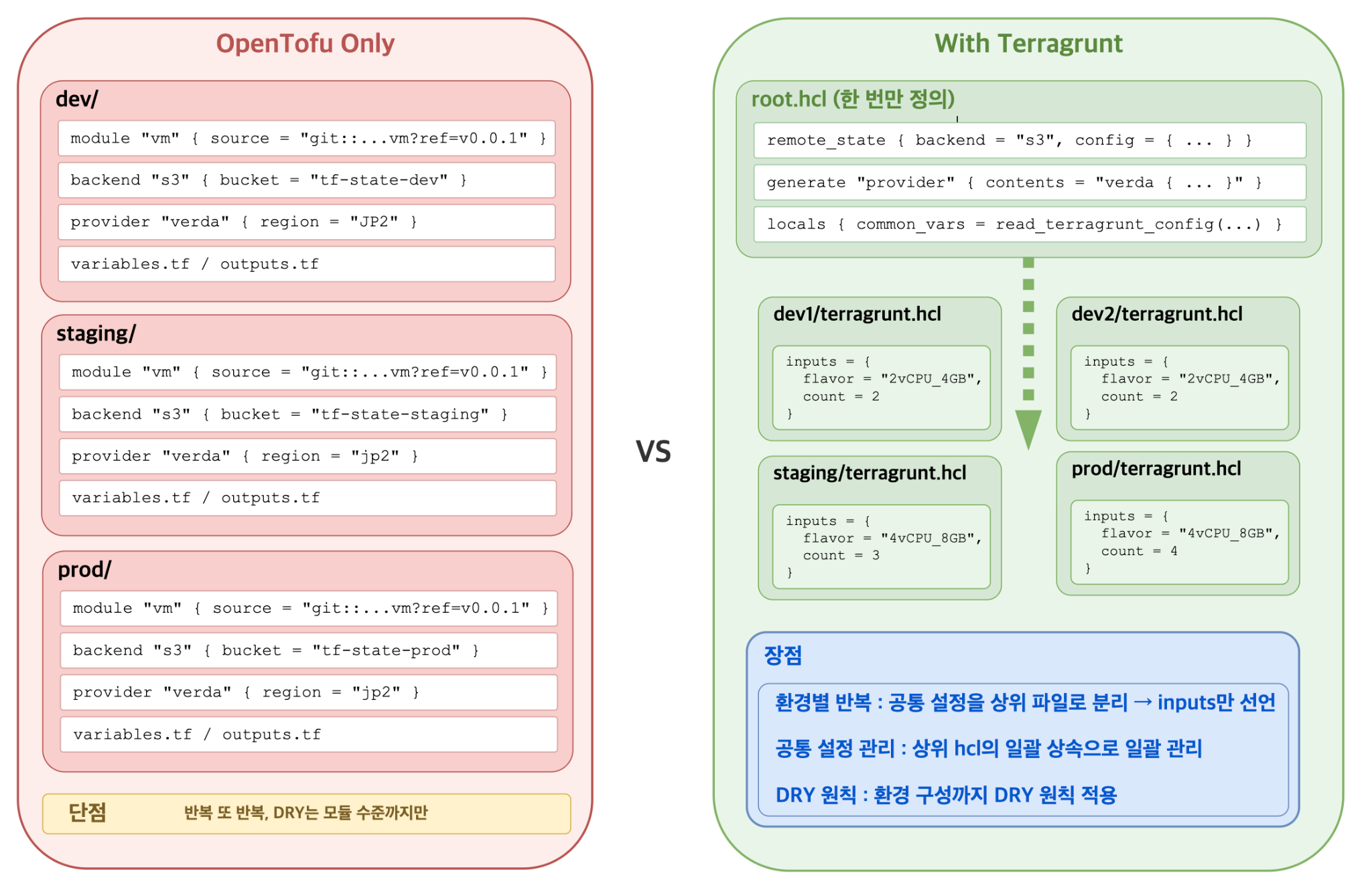
이와 같이 모듈화로 리소스 정의 중복을 줄이고, Terragrunt로 환경 중복을 줄입니다.
이사 시작
이사하기 위한 도구들이 준비되었으니, 이제 이사를 진행하며 어디에 신경을 썼는지 이야기해 보겠습니다.
빈집에 IaC를 도입할 때 만나는 가장 큰 허들은 이미 운영 중인 리소스를 코드 관리 체계 안으로 가져오는 일입니다. OpenTofu에서 import 기능을 제공하기는 하지만 운영 중인 리소스가 많을 때에는 현실적으로 수동으로 import하기는 어렵습니다. 리소스를 하나씩 식별하고, 설정 파일을 작성하고, 실제 인프라 상태와 연결하는 과정을 사람이 반복한다면 오래 걸릴 뿐 아니라 실수할 가능성도 높아집니다.
이에 저희는 이사를 두 단계로 나눠 진행하기로 했습니다.
첫 번째 단계에서는 먼저 import 과정을 자동화하고 서비스 하나를 선정해 이 서비스에 도구, 프로세스, 절차를 시범 적용해서 OpenTofu와 Terragrunt 기반 전체 파이프라인을 준비합니다.
두 번째 단계에서는 첫 번째 단계에서 검증한 모듈과 import 스크립트를 이용해 나머지 서비스에 빠르게 확산 적용합니다.
이사 1단계
import 스크립트 작성
기존 리소스를 IaC로 가져오는 일은 단순한 코드 변환 작업이 아니었습니다. 이미 운영 중인 인프라가 대상이었기 때문에 무엇보다 현재 상태에 영향을 끼치지 않고 안전하게 코드 관리 체계로 옮기는 것이 중요했습니다. 따라서 import 스크립트는 리소스를 조회하고, 코드로 변환하고, 실제 인프라 상태와 연결한 뒤, plan(Opentofu에서 실제 인프라에 적용될 예상 변경 사항을 미리 확인) 결과로 검증하는 흐름을 기준으로 설계했습니다.
이 과정에서 특히 신경 써야 했던 부분은 크게 두 가지였습니다. 첫 번째는 코드, state, 실제 인프라 리소스의 상태를 어떻게 일치시킬 것인가, 두 번째는 리소스별로 다른 구조와 의존 관계를 어떻게 반영할 것인가였습니다. 이 두 가지를 중심으로 import 과정에서 고려했던 점을 설명해 보겠습니다.
import 후 정규화로 코드, state 파일, 실제 인프라 리소스 상태 일치시키기
OpenTofu의 state 파일은 ‘코드에 선언한 리소스’와 ‘실제 클라우드에 존재하는 리소스’를 연결해 주는 정보입니다.
여기서 마주친 문제는 import로 가져온 후에도 코드와 state 파일과 실제 리소스의 값이 같지 않은 경우가 있었다는 점입니다. 네트워크 ID나 이미지 ID처럼 실제로는 같은 값을 가리키지만 표현 방식이 달라 plan에서 계속 변경 사항처럼 보이는 경우가 있었습니다. 이 상태를 그대로 두면 plan 결과를 신뢰하기 어려워지기 때문에 가져온 후 상태와 입력값을 정리하는 정규화 과정을 추가했습니다.
리소스별로 import 전략을 다르게
모든 리소스를 같은 방식으로 가져올 수는 없었습니다. 리전마다 리소스를 조회하는 방식이나 식별자 체계가 달랐고, 리소스 유형마다 import에 필요한 단위와 의존 관계도 달랐습니다. 예를 들어 VM은 개별 인스턴스를 기준으로 가져오면 되지만, LB는 LB 하나만 보면 안 됩니다. 리스너(listener), 풀(pool)처럼 함께 움직이는 리소스가 있기 때문입니다. DNS는 존(zone)과 레코드(record)의 관계를 유지해야 하고, 쿠버네티스는 클러스터(cluster)와 노드 풀(node pool)을 어떤 단위로 나누어 관리할지 결정해야 했습니다. IMON 알림 리소스도 팀, 알림 그룹, 알림 규칙, 알림 모니터가 계층 구조로 연결되어 있었습니다. 이에 저희는 다음과 같이 리소스별로 단계를 나누어 import하였습니다.
-
현재 리소스를 조회한다.
-
IaC로 관리할 대상과 제외할 대상을 구분한다.
-
코드 구조에 맞게 변환해 Terragrunt 파일을 생성한다.
-
실제 리소스를 OpenTofu state에 연결한다.
-
plan 결과를 확인해 불필요한 변경이 없는지 검증한다.
큰 흐름은 같지만, 세부 처리 방식은 리소스마다 다릅니다. 덕분에 리소스별 특성을 반영하면서도 전체 import 절차를 일관적으로 유지할 수 있었습니다.
import 과정에서 만난 이슈들
이와 같이 잘 신경 써서 설계한 import 스크립트를 실행하면 끝날 줄 알았지만, 실제 운영 환경은 그렇게 단순하지 않았습니다. 수백 개의 VM, LB, DNS 레코드를 코드로 가져오는 과정에서 예상하지 못한 문제들이 나타났습니다.
사람이 생성한 VM과 쿠버네티스가 자동으로 생성한 VM이 혼재하는 상태
OpenStack에는 사람이 직접 만든 VM과 쿠버네티스 서비스가 자동으로 만든 VM이 함께 존재했습니다. 둘은 같은 VM처럼 보이지만, 관리 주체가 다릅니다. 사람이 만든 VM은 IaC로 가져와도 되지만, 쿠버네티스가 관리하는 VM은 잘못 가져오면 클러스터가 기대하는 상태와 IaC가 관리하는 상태가 충돌할 수 있습니다.
이에 저희는 모든 VM을 무조건 가져오지 않고, 네이밍 패턴과 메타데이터를 기준으로 쿠버네티스가 생성한 VM은 가져오는 대상에서 제외했습니다. 이 필터링을 넣지 않았다면 IaC 도입 과정이 운영 중인 클러스터에 영향을 끼쳤을 것입니다.
IMON의 계층 구조
IMON의 알림은 단일 리소스가 아니라 다음과 같이 계층 구조로 구성되어 있습니다.
팀(team) → 알림 그룹(alert group) →알림 규칙(alert rule) → 알림 모니터(monitor)
이런 구조 때문에 단순히 알림 리소스를 한꺼번에 가져오는 방식으로는 제대로 가져올 수 없었습니다. 각 알림 규칙이 어느 알림 그룹에 속하는지, 각 모니터가 어떤 알림 규칙의 조건인지 함께 표현해야 했기 때문입니다.
이를 표현하기 위해 IMON 리소스는 아래와 같이 실제 계층과 비슷하게 디렉토리를 구성했습니다. 이렇게 구성하면 폴더 구조만 봐도 ‘이 알림 규칙이 어느 알림 그룹에 속하는지’를 바로 알 수 있습니다.
alert-groups/ line_alert_group_a/ terragrunt.hcl # Alert Group line_alert_rule_monitor_a/ terragrunt.hcl # Alert Rule + Monitor예상치 못한 프로바이더 이슈
프로바이더나 백엔드 동작이 실제 클라우드와 완전히 일치하지 않는 경우도 있었습니다.
-
LB 네이밍 컨벤션 충돌
-
원인 및 현상: 실제 클라우드에서는 로드밸런서 이름에 -과 _가 모두 허용되지만, 프로바이더의 백엔드 모듈에서는 _를 허용하지 않는 문제가 있었습니다. 이 때문에 기존에 _를 포함한 이름으로 생성된 LB 리소스를 가져올 때 오류가 발생했고, 모듈 내부에서 별도로 처리해야 했습니다.
-
해결 방법: 이 문제는 Provider 쪽 확인(validation) 로직을 수정해 provider에 기여하는 방식으로 해결했습니다.
-
-
UUID(universally unique identifier) 불일치
-
원인 및 현상: 리전마다 flavor_id, image_id, network_id의 UUID가 달라, import 후 plan에서 불필요한 변경이 계속 나타났습니다.
-
해결 방법: 이 문제는 모듈 내부에 매핑 로직을 추가해 해결했습니다. 사용자는 사람이 읽기 쉬운 이름을 입력하고, 모듈이 리전별 실제 ID로 변환하도록 만들었습니다. 덕분에 코드의 가독성도 좋아지고, import 후 발생하던 가짜 차이(diff)도 줄일 수 있었습니다.
-
이사 2단계
첫 번째 단계에서 만든 import 스크립트와 정규화 스크립트, 필터링 규칙, 모듈 보정 로직은 결과적으로 2단계에서 IaC를 다른 서비스로 확산하는 데 사용할 수 있는 중요한 자산이 되었습니다. 이 자산들은 기존 리소스를 코드로 전환하는 진입 장벽을 낮췄고, 팀마다 다르게 관리하고 있던 인프라를 OpenTofu와 Terragrunt를 결합해 만든 하나의 흐름 안으로 가져올 수 있었습니다.
IaC 전파: 익숙한 UI에서 코드로 넘어가기
IaC를 서비스 팀에 전파하기 위해 가장 먼저 정리한 것은 변경 흐름이었습니다. 단순히 OpenTofu 코드를 제공하는 것이 아니라, PR을 만들면 plan이 자동으로 생성되고, 리뷰와 승인 후 적용되는 절차를 표준화했습니다. 서비스 팀 입장에서는 새로운 도구를 배우는 것보다 ‘앞으로 인프라 변경은 이 흐름을 따르면 된다’는 예측 가능한 프로세스가 중요했기 때문입니다.
하지만 변경 흐름을 정리하는 것만으로 IaC가 자연스럽게 확산되지는 않았습니다. 모든 팀원이 곧바로 HCL을 능숙하게 작성할 수 있는 것은 아니었기 때문입니다. HCL에는 각 프로바이더마다 고유한 리소스 타입과 인자가 있어서 이를 한 번에 익혀서 사용하기는 어렵습니다. 특히 모니터링 관리의 경우 웹 대시보드에 익숙한 사용자가 많았기에 “이제부터 코드로만 알림을 만드세요”라고 하면, “대시보드가 더 편한데요”라는 반응이 나올 수밖에 없었습니다.
이에 저희는 단순히 “코드를 쓰세요”라고 요구하는 것이 아니라 어떻게 하면 서비스 팀이 자연스럽게 “코드로 관리하는 게 더 편하네요”라고 느낄 수 있을지 전파 방식을 고민했습니다. 그 고민의 결과를 몇 가지 소개합니다.
기존 리소스 import 지원: 좋은 예시가 최고의 문서
사람들은 잘 만들어진 예시를 통해 쉽게 학습합니다. 이를 이용하기 위해 복잡한 import 작업은 SRE 팀이 먼저 수행한 뒤 각 팀에게 “여러분 서비스의 VM이 코드로는 이렇게 생겼습니다”라고 보여줬습니다. 빈 에디터에서 HCL을 처음부터 작성하는 것과 자기 서비스의 실제 리소스가 이미 코드로 표현된 상태에서 시작하는 것은 진입 장벽이 전혀 다릅니다.
Chrome 확장 프로그램: 클릭하던 그 화면에서 코드가 나오도록
모니터링 관리는 사용자 대부분이 웹 대시보드에서만 알림을 만들고 관리해 왔습니다. CLI나 API를 거치지 않고 브라우저에서 모든 작업이 끝나는 환경에 익숙한 사람들이었습니다. 이 사용자들에게 “에디터를 열고 HCL을 작성하세요”는 너무 먼 이야기였습니다.
그래서 저희는 사용자가 이미 머무는 곳, 즉 웹 브라우저 안에서 코드를 만나도록 Chrome 확장 프로그램(extension)을 만들었습니다. 사용자가 IMON2 웹 대시보드에서 알림 규칙 페이지를 열면, 확장 프로그램이 DOM(document object model)에서 설정값을 읽어 OpenTofu HCL 코드를 자동 생성합니다. 사용자는 익숙한 화면에서 설정을 확인하면서, 옆 패널에 나타난 코드를 복사해 PR로 올리면 됩니다. 핵심은 ‘웹 UI를 버려라’가 아니라 ‘웹 UI에서 시작해서 코드로 끝내라’는 접근이었습니다. 즉, Chrome 확장 프로그램은 웹 UI를 대체하기 위한 도구가 아니라 기존 운영 습관과 IaC 워크플로 사이를 연결하는 다리 역할을 했습니다.
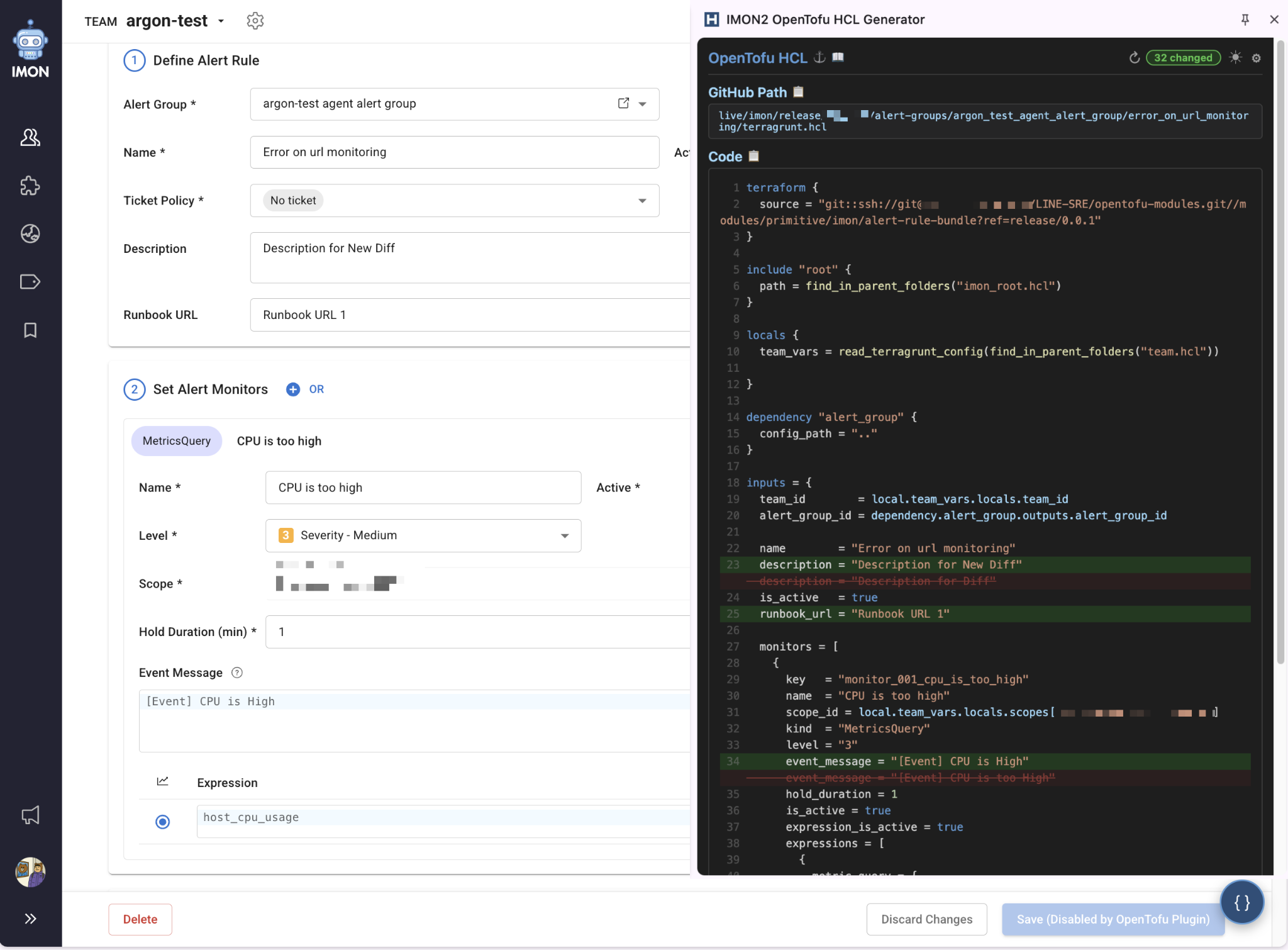 |
Opentalk: SRE에서 서비스 팀으로 이어지는 전파
도구와 자동화만으로 전파가 완성되는 것은 아닙니다. 사람 사이에 직접 공유하는 것도 필요합니다. 저희 회사 SRE들은 격주로 ‘Opentalk’라는 기술 공유 세션을 운영하고 있습니다. 이 세션에서 IaC 도입 배경, 저장소 구조 설계, PR 기반 변경 워크플로 등을 공유했습니다. 세션 발표 후 받은 피드백은 실제 개선으로 이어졌습니다. 이와 같이 사용하는 사람들의 목소리를 직접 듣고 반영하는 과정이 있었기에, 도구와 프로세스를 현장에 더 잘 맞는 형태로 다듬을 수 있었습니다.
전파 경로도 단계적으로 설계했습니다. 처음부터 모든 서비스 팀에 한꺼번에 설명하는 것보다 ‘Opentalk’을 통해 각 서비스 담당 SRE에게 IaC 운영 방식을 먼저 공유하면, 해당 서비스의 인프라를 이미 잘 알고 있는 담당 SRE가 팀 상황에 맞게 안내하는 편이 훨씬 효과적일 것이라 생각했습니다.
블로그
이 글 자체도 전파 전략의 일부입니다. 구조와 결정 과정을 글로 풀어두면, 새로 합류하는 팀원이나 IaC 도입을 고민하는 다른 팀이 ‘왜 이렇게 만들었는지’를 코드 밖에서도 이해할 수 있습니다. 코드는 ‘무엇을’ 설명하고, 이 블로그는 ‘왜’를 설명합니다.
도입 후, 달라진 것들
IaC가 자리를 잡으면서, 변화는 시스템에서 시작해 사람에게까지 이어졌습니다.
운영 변경: 모든 변경은 Git에 남습니다
가장 먼저 달라진 것은 변경 이력입니다. 모든 인프라 변경에 작성자, 시간, 이유, 리뷰어가 남습니다. “이 서버 누가 만들었지?”라는 질문은 더 이상 담당자의 기억을 따라가지 않아도 됩니다. Git 로그와 PR을 보면 됩니다.
commit a1b2c3d Author: engineer-a Date: 2024-12-15 feat: add staging VM for payment-service - 4vCPU_8GB, Rocky Linux 9.4 - Requested by: payment team (#TICKET-1234) Reviewed-by: engineer-bIaC의 가장 큰 가치 중 하나는 PR을 통한 리뷰 프로세스입니다. 인프라 변경이 코드로 표현되면, 피드백 루프가 생깁니다. 예를 들어, 누군가 새 VM을 만드는 PR을 올렸을 때 다음과 같은 피드백이 오갈 수 있습니다.
“custom_tag가 빠졌습니다. DB ACL 설정을 위해 해당 tag 추가가 필요합니다.”
“BMT(Benchmark Test) 결과를 검토해보니 트래픽에 따라 메모리를 많이 쓰는 패턴이 보여서, 이 flavor 말고 Memory Intensive로 바꾸는 게 좋을 것 같은데 어떠세요?”
인프라 생성 작업 시 이런 피드백이 오간다는 것은 콘솔에서 혼자 클릭할 때는 불가능했던 일입니다. 덕분에 잘못된 설정이 인프라에 반영되기 전에 걸러집니다. 여기에다 별도 CODEOWNERS 설정을 이용해 각 저장소의 필수 리뷰어를 지정하면 리뷰 없이는 머지할 수 없도록 기술적으로 강제할 수 있습니다. 이 리뷰 프로세스는 자동화된 CI/CD 파이프라인과 결합되어 다음과 같이 작동합니다.
-
Plan: PR 열리면 자동 실행(변경 사항의 영향을 미리 확인)
-
Review: 팀이 Diff 리뷰(리뷰어가 변경 내용을 검토하고 피드백)
-
Apply: 머지 시 자동 배포(승인된 변경만 인프라에 반영)
-
Drift Check: 매일 자동 스캔(코드와 실제 인프라 간 차이를 감지)
위와 같은 리뷰 프로세스가 적용된 워크플로가 각 서비스별, 환경별(Verda, Flava, IMON)로 분리돼 운영됩니다. 추가로 상태 잠금이 걸렸을 때를 위한 ‘force-unlock’ 워크플로도 모든 프로젝트에 구비되어 있어 상태 잠금 복구를 위해 서버에 직접 접속할 필요가 없습니다.
각 단계에서 나오는 결과물은 모두 투명하게 공유됩니다. plan 결과는 PR에 자동으로 코멘트되어 ‘이 PR이 머지되면 무슨 일이 생기는지’ 모든 팀원이 확인할 수 있습니다. Apply 결과는 배포 후 Slack으로 전달되어 성공/실패를 즉시 확인할 수 있고, Drift Check는 매일 실행되어 콘솔에서 발생한 변경을 전체 차이(diff)와 함께 Slack으로 알림합니다.
Drift Check: 수동 변경을 자동으로 감지
IaC의 혜택은 리소스 생성과 변경에서 끝나지 않았습니다. 앞서 소개한 CI/CD 파이프라인의 네 번째 단계인 Drift Check를 통해 매일 코드와 실제 인프라의 차이를 감지하고 Slack으로 알림을 보냅니다.
여기서 Drift란, 코드에 선언된 상태와 실제 클라우드의 상태가 일치하지 않는 현상을 말합니다. 누군가 콘솔에서 직접 수정하면 발생합니다. 예를 들어, 서비스 오픈 전 테스트 단계에서 누군가 빠르게 확인해 보려고 콘솔에서 DNS 레코드의 IP를 변경했다고 가정하겠습니다. 테스트 후 복원하려 했지만 다른 준비 작업에 밀려 잊어버린다면 이 변경은 추적과 발견이 힘들 텐데요. 하지만 코드에는 기존 IP가 그대로 선언되어 있기 때문에, Drift Check이 서비스 오픈 전에 이 차이를 감지하고 사용자에게 Slack으로 알림을 보냅니다. 그 덕분에 서비스가 오픈되기 전에 원복할 수 있고, 사용자 트래픽이 잘못된 IP로 흘러가는 상황을 미리 예방할 수 있습니다.
모니터링까지 코드로
모니터링 알림도 코드로 관리하면서, 임계치를 변경할 때 PR 하나로 여러 알림을 한꺼번에 수정할 수 있게 되었습니다. 변경 이력에 ‘왜 이 임계치를 바꿨는지’가 커밋 메시지로 남기 때문에 나중에 ‘이 값 누가 왜 바꿨지?’를 추적할 필요가 없어졌습니다. 새 서비스에 동일한 알림 구조를 만들 때에도 기존 코드를 복사해서 값만 바꾸면 됩니다. 대시보드에서 하나씩 클릭하며 만들 때 생기던 미세한 설정 차이도 사라졌습니다. 인프라뿐 아니라 모니터링까지 코드로 관리하면서, 서비스 전체의 운영 형상이 한 저장소 안에서 추적 가능해졌습니다.
문서를 대체한 코드
이 변화는 시스템에서 그치지 않았습니다. 이전에는 새 팀원이 합류하면 인프라 구성을 위키 문서와 구두 설명으로 전달해야 했습니다. 어떤 VM이 어떤 서비스에 속하는지, LB 설정은 어떻게 되어 있는지, 이 알림 규칙은 왜 이런 임계치로 설정되어 있는지를 사람이 직접 설명해야 했습니다.
이젠 저장소를 보여주면 됩니다. 코드를 읽으면 인프라의 현재 구성이 보이고, PR 이력을 따라가면 ‘왜 이렇게 바뀌었는지’까지 파악할 수 있습니다. 과거 PR에 남은 리뷰 코멘트에는 의사결정의 맥락이 담겨 있기 때문입니다. ‘이 flavor 대신 Memory Intensive를 쓴 이유’, ‘이 알림 임계치를 낮춘 배경’ 같은 것들을 별도 문서로 남기지 않아도 이력 안에 그대로 남아 있습니다. 시니어만 알던 인프라 지식이 코드와 이력을 통해 자연스럽게 공유되면서, 온보딩에 필요한 시간이 줄었습니다.
인프라 셀프서비스의 시작
IaC 도입 전에는 모든 인프라 변경이 SRE 팀을 거쳐야 했습니다. 하지만 모듈을 갖추고 전파하기 시작하면서 변화가 나타났습니다. A 서비스를 담당하는 개발 팀은 이제 직접 Terragrunt 코드를 작성하고 PR을 올립니다. SRE 팀은 리뷰어로 참여할 뿐 코드 작성까지 대신하지 않습니다.
다른 팀들은 후술할 AI 에이전트를 이용해 인프라를 변경하려고 움직이고 있습니다. Slack에서 자연어로 요청하면 에이전트가 코드를 생성하고 PR을 열어주기 때문에 HCL 문법을 몰라도 IaC 워크플로에 참여할 수 있습니다. 직접 코드를 작성하든 AI 에이전트를 경유하든 모든 변경은 같은 GitOps 파이프라인을 거칩니다. 진입 경로는 달라도 리뷰와 추적 원칙은 동일하게 적용됩니다.
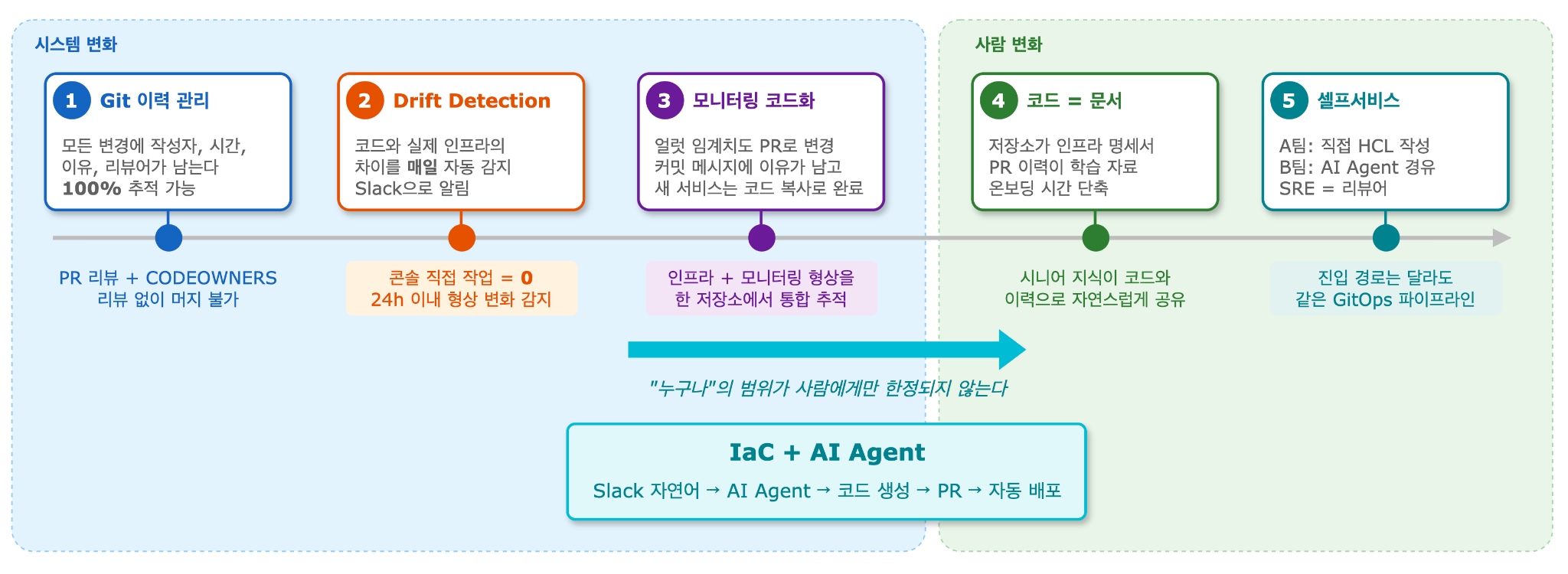
인프라의 모든 것이 코드로 표현되고 누구나 같은 방식으로 읽고 변경할 수 있는 체계가 만들어졌습니다. 그리고 여기서 ‘누구나’의 범위가 사람에게만 한정되지 않는다는 것을 곧 깨달았습니다.
다음 단계: IaC와 AI 에이전트의 결합
IaC로 인프라를 관리하면 한 가지 사실을 알 수 있습니다. 코드로 선언한 인프라는 사람만 읽는 것이 아니라 AI도 똑같이 읽을 수 있다는 점입니다. “A 서비스 두 대 더 늘려주세요”, “B 서비스에 LB 추가해 주세요”와 같은 반복 요청은 패턴이 정해져 있습니다. AI 에이전트가 처리할 수 있는 영역입니다. 그래서 AI 에이전트에 OpenTofu 저장소를 MCP(model context protocol)로 연결하고, Slack에서 자연어로 인프라를 변경하는 봇을 만들었습니다.
Slack에서 자연어로 요청하면 에이전트가 기존 코드 패턴을 참고해 Terragrunt 코드를 생성하고 PR을 엽니다. plan 결과는 Slack으로 공유되고, 사람이 리뷰하고 승인하면 자동으로 배포됩니다.
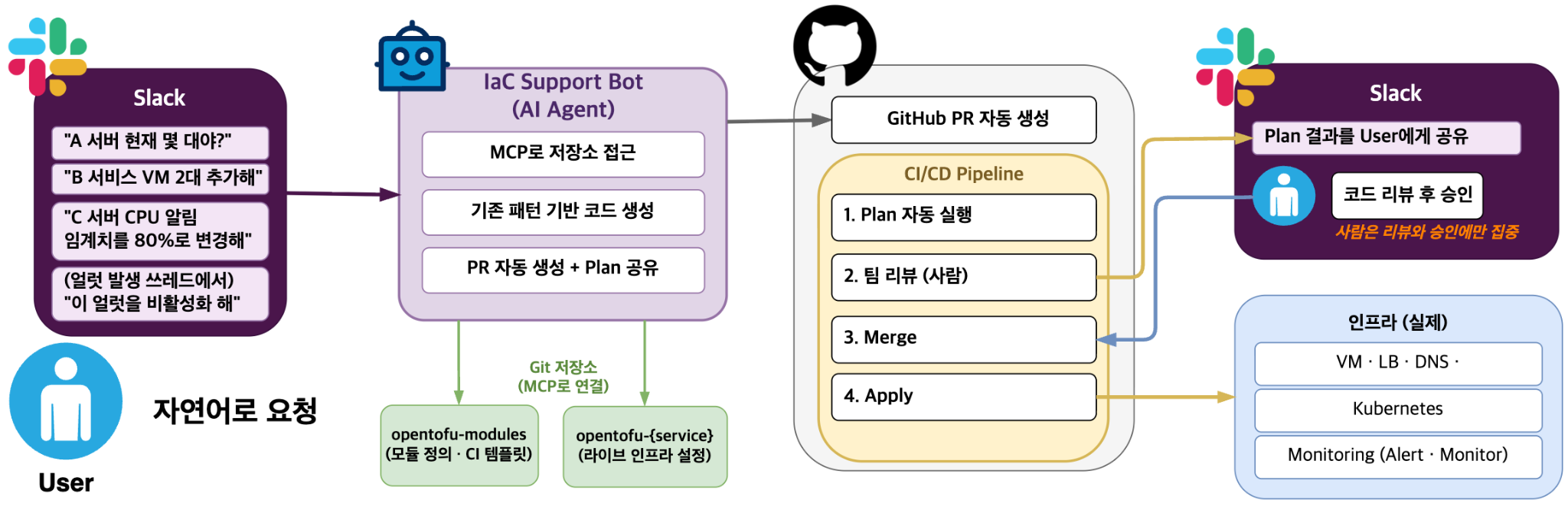
아래는 활용 예시입니다. 코드를 직접 작성할 필요 없이, Slack에서 서버 정보를 확인하고, 서버 수량을 늘려달라고 말하면 나머지는 에이전트가 다 준비합니다.
자연어 요청 외에도 모니터링 알림을 트리거로 AI 에이전트가 자동으로 대응 코드를 생성하는 시나리오도 가능합니다.
| 1. 알림 수신 | 온콜 담당자가 Slack 알림 확인 | AI 에이전트가 알림을 자동으로 수신 |
| 2. 상황 파악 | 콘솔에 접속해 현재 VM 수/스펙 확인 | 에이전트가 IaC를 통해 즉시 파악 |
| 3. 대응 | SRE에게 스케일 아웃 요청 또는 직접 콘솔에서 VM 추가 | 에이전트가 스케일 아웃 코드를 자동으로 생성하고 PR 오픈 |
| 4. 리뷰 | 사후에 “누가 서버를 왜 추가했지?” | PR에 변경 이유, 알림, plan 결과가 모두 기록 |
| 소요 시간 | 알림 확인부터 반영까지 수십 분 | PR 생성까지 수 분, 승인 즉시 반영 |
이처럼 사람이 요청하든 모니터링 시스템이 트리거하든 코드는 AI 에이전트가 작성합니다. 사람은 리뷰와 승인에만 집중하면 됩니다.
IaC 도입을 고려하시는 분들께
콘솔에서 작업하는 것이 귀찮고 실수할까 두려운 분이라면 누구든지 시도해 보는 것을 추천합니다. 다만, 도입 전 알아두면 좋은 점들이 있습니다.
도입하면 작은 변경도 절차를 거쳐야 합니다
“VM 하나 스펙을 올려주세요”와 같은 요청은 IaC 이전이라면 콘솔에서 클릭 두세 번이면 끝납니다. 하지만 IaC 체계에서는 ‘코드 수정 → PR 생성 → 리뷰 → 머지 → 적용’이라는 단계를 거칩니다. 처음엔 번거로워 보일 수 있지만 이는 확실한 장점입니다. 처음 온보딩한 사람도 코드를 보면 인프라 구성을 파악할 수 있고, 정해진 절차를 따르면 안전하게 변경할 수 있습니다. 시니어만 알던 지식이 코드로 자연스럽게 공유되는 셈입니다.
팀 전체가 IaC 문화를 받아들여야 합니다
IaC 도입은 기술의 문제가 아니라 문화의 문제입니다. 팀원 중 한 명이라도 콘솔에서 직접 수정하면, 코드와 실제 인프라 사이에 차이가 생기기 때문입니다. 따라서 IaC 문화와 어긋나는 콘솔 변경 작업은 긴급 대응처럼 불가피한 경우로만 제한하고, 변경 후에는 반드시 IaC 코드에 반영해 코드와 실제 상태를 다시 일치시켜야 합니다.
설령 이 반영 작업을 놓치더라도 Drift Check가 수동 변경을 잡아내 주므로, 문화를 정착시키는 든든한 안전장치가 되어 줍니다. 또한 의도적으로 코드와 다른 상태를 유지해야 하는 리소스는 별도 ignore 파일(예: .driftignore)에 등록해서 Drift Check 대상에서 제외하고 별도 예외로 관리할 수 있습니다.
운영 규모와 상관 없이 일단 시작해 보세요
운영 규모가 작다면 쉽게 import할 수 있기 때문에 빠르게 시작할 수 있습니다. 반대로 운영 규모가 크다면 추적이 어려워 발생할 수 있는 이력 관리와 장애 위험을 줄일 수 있기 때문에 한 번 시작해 보길 권합니다. 또한 IaC 도입은 앞서 보여드린 것처럼 사람과 AI 에이전트가 똑같이 볼 수 있는 뷰를 설정하는 것이기 때문에 AI 자동화의 발판을 마련하는 것이기도 합니다.
마치며
처음엔 막막했습니다. 운영 중인 리소스를 코드로 옮긴다는 것은 달리는 기차의 바퀴를 갈아끼우는 느낌이었습니다. 1단계에서 처음으로 서비스 하나를 옮기는 데 한 달이 걸렸습니다. 도구를 고르고, 파이프라인을 짜고, 상태 정규화 스크립트를 만들고, 가드레일을 세웠습니다. 하지만 그 한 달이 없었다면 2단계도 없었을 것입니다. 같은 기간에 서비스를 네 개 더 올릴 수 있었던 이유는 1단계에서 만들어 놓은 기반 덕분이었습니다.
지금은 인프라 변경이 무서운 일이 아닙니다. 코드를 고치고, PR을 올리고, 리뷰를 받고, 머지한다. 매일 하던 개발 워크플로 그대로 입니다. 이제는 누군가가 “이 서버 누가 만들었나요?”라고 물으면 Git 로그를 보여주면 됩니다.
사실 이 모든 여정은 Verda와 IMON의 Terraform 프로바이더를 만들어준 SRE 9팀 덕분에 시작할 수 있었습니다. 사내 클라우드 플랫폼을 코드로 다룰 수 있게 연결해 준 프로바이더가 없었다면, 이 글도 없었을 겁니다. 이 지면을 빌려 감사 인사를 전합니다.
이 글에서 소개한 사례가 저희 팀의 사례로만 한정되지 않도록 IaC 도입을 고민하시는 모든 분들의 첫걸음에 이 글이 참고가 되기를 바라며 마치겠습니다. 긴 글 읽어주셔서 감사합니다.
Tech-Verse 2026 개최 안내 — 6월 29일

이 글은 Tech-Verse 2026 이벤트의 공식 기사로 공개되었습니다. Tech-Verse 2026은 LY Corporation에서 개최하는 기술 컨퍼런스입니다. 혁신적인 기술적 도전 과정과 현장의 생생한 인사이트를 공유합니다.
YouTube LIVE로 생중계할 예정이니 관심 있으신 분들은 꼭 시청해 주세요.










![[G-브리핑] 컴투스, 임직원 참여형 ESG 플로깅 활동](https://pimg.mk.co.kr/news/cms/202606/11/news-p.v1.20260611.0f1bb9233318459cb7ad7f04a40a2d5c_R.jpg)


 English (US) ·
English (US) · 